What is Parquet?

Apache Parquet is an open-source file format often used for big data in Hadoop clusters. Parquet stores data using a flat compressed, columnar storage data format. The Apache Spark provides high-level APIs for developers to use, including support for Java, Scala, Python and R. Parquet is well suited to efficiently storing nested data structures.
Characteristics of Parquet
Understanding the characteristics of Parquet can shed light on why it’s such an attractive choice for data professionals:
- Columnar Storage: Parquet stores data in columns, which is ideal for analytical queries. With columnar storage, each column is stored independently, allowing for much faster access to specific data points compared to row-based formats.
- Efficient Compression: One of the most notable features of Parquet is its ability to compress data effectively. Columnar storage allows similar data types to be stored together, making compression algorithms like Snappy, Gzip, and LZO highly effective. This reduces the overall file size and leads to savings in storage costs.
- Schema Support: Parquet files include embedded metadata that describes the structure of the data, which simplifies processing and ensures consistency across various systems. The schema is stored along with the data, making it easier for data processing tools to understand and interpret the data correctly.
- Open-Source and Cross-Platform: Parquet is an open-source format, and its flexibility ensures it works across different data platforms and processing frameworks. Being widely adopted in the open-source community, it is supported by various big data tools and platforms, making it highly versatile.
Benefits of Parquet
The advantages of using Parquet go beyond its technical characteristics, offering real value to organizations dealing with large volumes of data:
- Improved Performance: Parquet files support predicate pushdown, a feature that allows queries to skip unnecessary data and only scan the relevant sections of the file. This results in faster query performance compared to other formats like CSV, especially when dealing with complex analytical queries.
- Lower Storage Costs: The compression benefits of Parquet are significant. Because data is stored more efficiently, it takes up less space, which means reduced storage costs. This is especially important in big data environments where the volume of data can quickly become enormous.
- Optimized for Analytical Workloads: Parquet was specifically built for analytical workloads. In environments where you need to run frequent queries and large-scale data processing, Parquet shines as the format of choice. It allows organizations to process data faster and more efficiently.
- Compatibility with Data Processing Frameworks: Parquet integrates seamlessly with popular data processing frameworks like Apache Spark, Apache Hive, and Apache Flink. This makes it a natural choice for organizations already using these tools.
Advantages of Storing Data in a Columnar Format
Storing data in a columnar format like Parquet has significant benefits over traditional row-based formats, such as CSV:
- Efficient Query Performance: One of the key advantages of columnar formats is that only the relevant columns are read during queries, which significantly speeds up data retrieval. In contrast, row-based formats require the entire file to be read, even if only a small portion of the data is needed.
- Better Compression Rates: Since data in a columnar format is often of the same type and structure, it can be compressed more efficiently. This reduces the overall storage footprint of the data and minimizes the number of resources needed for data transfer and storage.
- Flexibility with Complex Data Structures: Parquet allows for the storage of complex nested data structures, such as arrays, maps, and structs. This capability makes it particularly useful for storing data in modern, distributed systems, where relationships between different data points can be intricate.
Parquet vs. CSV: Key Differences
When comparing Parquet to the more traditional CSV format, several important differences come to light:
- Storage Efficiency: Parquet files are much more space-efficient than CSV files, primarily because of their columnar structure and better compression techniques. A CSV file can be much larger, especially with large datasets.
- Query Performance: Parquet’s columnar format allows for faster and more targeted queries, while CSV files require loading the entire dataset into memory. This can drastically slow down query performance, especially when dealing with large datasets.
- Scalability: Parquet is far more scalable than CSV. As your dataset grows into the terabytes or even petabytes, Parquet handles the size and complexity far better than CSV.
- Data Integrity: With Parquet, the metadata and schema are stored alongside the data, which helps maintain the integrity and structure of the dataset. In contrast, CSV files lack schema information, which can lead to inconsistencies and errors when data is transferred across different systems.
Storage
A Parquet file consists of row groups. Row groups contain a subset of data stored as pages. Pages are grouped into column chunks. Columns chunks contain metadata information that includes the number of defined values, their size, and statistics such as the number of null and min/max values.
Parquet Data Types
Parquet supports multiple 320-bit data types. These include the following:
- BOOLEAN: 1-bit boolean
- INT32: 32-bit signed ints
- INT64: 64-bit signed ints
- INT96: 96-bit signed ints
- FLOAT: IEEE 32-bit floating point values
- DOUBLE: IEEE 64-bit floating point values
- BYTE_ARRAY: arbitrarily long byte arrays
- FIXED_LEN_BYTE_ARRAY: fixed length byte arrays
Compression in Parquet
Parquet stores large datasets, so compression is an important feature of this file format. Different compression algorithms can be applied per column. The following compression codecs are provided with the base distribution:
- GZIP: is suited to long-term static storage such as data archival. GZIP provides greater compression than Snappy but consumes more CPU resources.
- Snappy: is a good choice for hot data that is often accessed. Decompression speeds for Snappy are shorter than GZIP. Snappy is splittable (unlike GZIP).
- LZO: is a good choice if your application requires high decompression speeds.
Hadoop
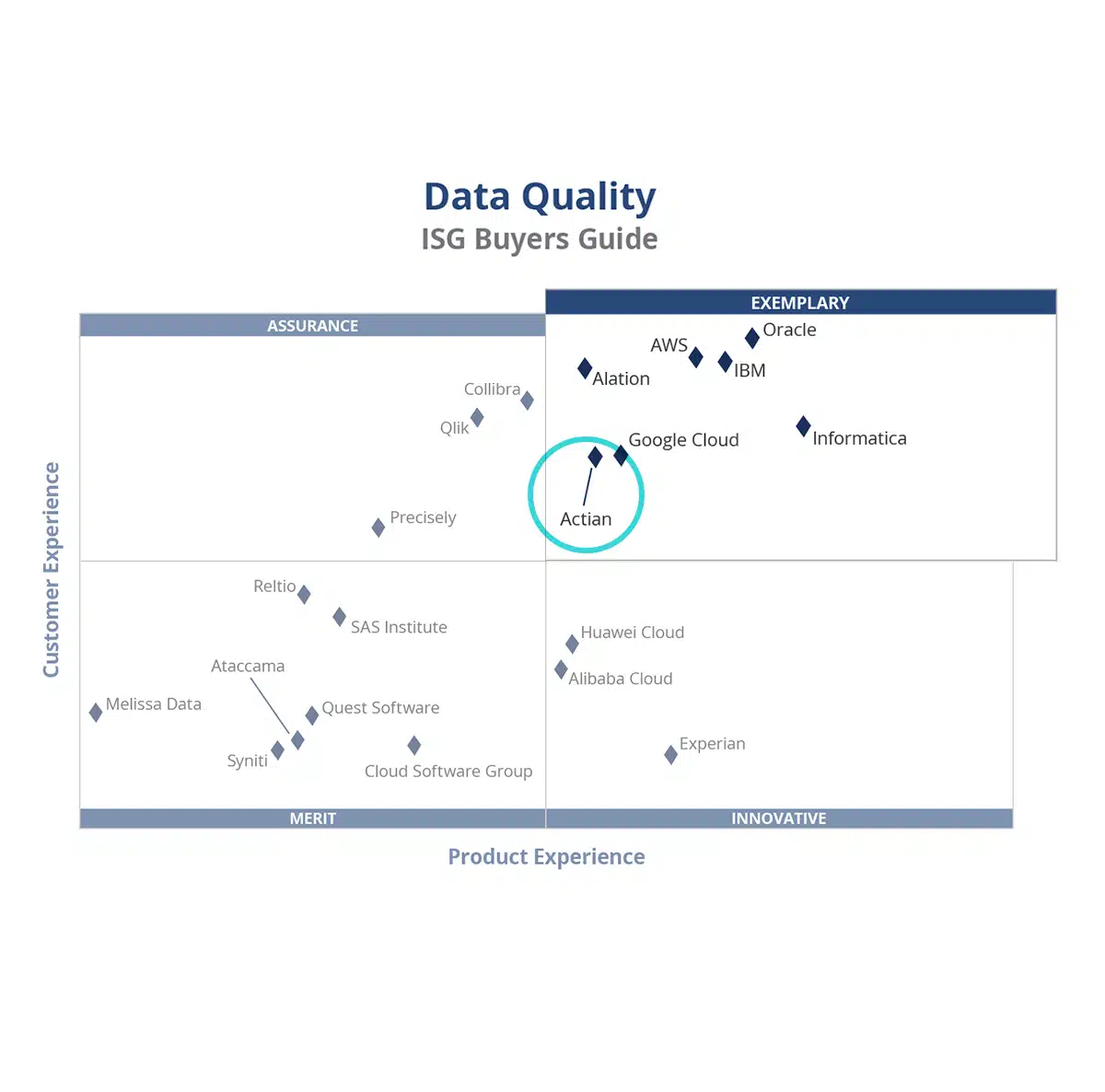
Hadoop provides an open-source platform that scales horizontally to accommodate big data workloads. Parquet was developed primarily for Hadoop environments. Many organizations created Hadoop clusters in the heyday of the big data movement. Unfortunately, Hadoop tuning skills have become scarce, so organizations are moving their Parquet data to more modern architectures. Hadoop systems such as Pig, Hive and Spark use Parquet. Spark provides the best API to access Parquet data. Modern data warehousing systems such as the Actian Data Platform use a Spark connector to access Parquet data wherever it resides, on-premise or in the cloud.
Actian Data Platform
Using a Spark connector, the Actian Data Platform can access Parquet as an external object. Predicates can be pushed down to Parquet to improve access speeds. External Parquet data is easy to load because requests can be wrapped in SQL. Loading parquet data into tables provides the fastest access to data thanks to vector processing that loads columnar data into the CPU cache across a server or cluster to maximize the parallel processing of queries. Benchmarks have shown the Actian Data Platform can scale an order of magnitude beyond Hive.
In the examples below, a Parquet external data source is mapped as an external table before loading its data into an internal table for faster application access.
Loading Parquet Data From Google Cloud Storage:
DROP TABLE IF EXISTS pemdata_gs;
CREATE EXTERNAL TABLE pemdata_gs (
timeperiod VARCHAR(20),
flow1 VARCHAR(20),
flow2 VARCHAR(20),
occupancy1 VARCHAR(20),
speed1 VARCHAR(20)
) using spark
WITH
reference=’gs://avpemdata/part*.parquet’,
format=’parquet’;
DROP TABLE IF EXISTS pemdata;
CREATE TABLE pemdata (
timeperiod TIMESTAMP,
flow1 VARCHAR(20),
flow2 VARCHAR(20),
occupancy1 VARCHAR(20),
speed1 VARCHAR(20)
);
Loading Parquet Data From Azure Blob Storage:
DROP TABLE IF EXISTS pemdata_adl;
CREATE EXTERNAL TABLE pemdata_adl (
timeperiod VARCHAR(20),
flow1 VARCHAR(20),
flow2 VARCHAR(20),
occupancy1 VARCHAR(20),
speed1 VARCHAR(20)
) using spark
WITH
reference=’abfs://parquetdata@mydata.dfs.core.windows.net//part*.parquet’,
format=’parquet’;
DROP TABLE IF EXISTS pemdata;
CREATE TABLE pemdata (
timeperiod TIMESTAMP,
flow1 VACHAR(20),
flow2 VARCHAR(20),
occupancy1 VARCHAR(20),
speed1 VARCHAR(20)
);
INSERT INTO pemdata SELECT * FROM pemdata_adl;
Loading Parquet Data From AWS S3 Storage:
DROP TABLE IF EXISTS pemdata_s3;
CREATE EXTERNAL TABLE pemdata_s3 (
timeperiod VARCHAR(20),
flow1 VARCHAR(20),
flow2 VARCHAR(20),
occupancy1 VARCHAR(20),
speed1 VARCHAR(20)
) using spark
WITH
reference=’s3a://avpemdata/part*.parquet’,
format=’parquet’;
DROP TABLE IF EXISTS pemdata;
CREATE TABLE pemdata (
timeperiod TIMESTAMP,
flow1 VARCHAR(20),
flow2 VARCHAR(20),
occupancy1 VARCHAR(20),
speed1 VARCHAR(20)
);
INSERT INTO pemdata SELECT * FROM pemdata_s3;