
La gestion efficace, efficiente et économique des données est essentielle à la réussite d'une organisation. Les données soutiennent les opinions expertes des personnes et fournissent des informations pour les décisions des technologies émergentes telles que l'apprentissage automatique, informatique décisionnelleet les solutions d'intelligence artificielle.
La gestion des données historiques et cumulatives peut s'avérer difficile. Les données collectées auprès de nombreuses sources, dans des formats variés et selon des conventions de dénomination différentes, représentent globalement un défi pour l'organisation. Il est donc difficile de donner une signification cohérente aux données et de les rendre accessibles aux personnes et aux applications qui les utilisent pour prendre des décisions. Une architecture d'entrepôt de données peut aider à résoudre ces problèmes complexes.
Qu'est-ce que l'architecture d'un entrepôt de données ?
L'architecture d'un entrepôt de données consiste à planifier, concevoir, construire et gérer les processus opérationnels quotidiens relatifs à l'utilisation des données à des fins d'intelligence organisationnelle et d'support décision. L'architecture d'un entrepôt de données permet de créer une source unique de vérité pour d'importants volumes de données provenant de sources diverses et variées. Les données sont ensuite transformées en informations et les informations sont transformées en connaissances pour l'analyse au sein de l'architecture de l'entrepôt de données.
Le cycle de vie des données comprend la collecte de données à partir de sources identifiées, la gestion de l'intégrité des données et la réconciliation, le stockage des données, le transfert des données et l'amélioration continue des données en fonction de la maturité de l'organisation, de l'analyse et des besoins décisionnels. L'architecture de l'entrepôt de données doit support ces activités et d'autres aspects de la gestion du cycle de vie des données.
Les architectures d'entrepôt de données sont généralement conçues pour être partie prenante, telles que les ventes, le marketing et autres. Bien qu'elle utilise des données communes, chaque partie prenante a des besoins différents en matière de modélisation et d'analyse des données pour prendre ses décisions. Cela inclut les personnes qui utilisent divers outils ainsi que la manière dont les technologies ou les applications consomment les données pour les traduire en informations et en décisions.
Types d'architectures d'entrepôts de données
Ce n'est pas une bonne pratique que de support traitement analytique avec une base de données transactionnelle en raison des problèmes de performance. Les bases de données transactionnelles sont optimisées pour traiter d'énormes volumes de transactions en temps réel, tandis que les bases de données analytiques sont optimisées pour les requêtes longues et gourmandes en ressources. C'est pourquoi les données transactionnelles doivent être intégrées dans la base de données de l'entrepôt de données plutôt que de répondre à la fois aux besoins transactionnels et analytiques.
Il existe différents modèles d'entrepôt de données, tels que
Architecture de base de l'entrepôt de données - simple niveau
Cette architecture minimise la quantité de données stockées et les redondances de données. Elle n'est pas couramment utilisée mais peut répondre aux besoins de certaines petites organisations qui n'ont pas besoin d'un accès aux données à l'échelle de l'entreprise. Des problèmes de performance se posent souvent lorsque le traitement analytique et le traitement transactionnel ne sont pas séparés.
Architecture de l'entrepôt de données avec un dépôt centralisé - Deux niveaux
Cette architecture utilise la mise à disposition pour extraire des données spécifiques, les transformer en vue de leur utilisation et les charger dans un entrepôt de données. Ce processus est appelé extraction, transformation et chargement(ETL). L'une des sources d'extraction peut être une base de données transactionnelle. Les informations sont sauvegardées dans un dépôt individuel logiquement centralisé, un entrepôt de données, qui est associé à des outils analytiques. Les marts de données peuvent être inclus dans une architecture d'entrepôt de données à deux niveaux afin de fournir des applications d'utilisateur commerciale ciblées.
Architecture de l'entrepôt de données avec un dépôt centralisé et un serveur OLAP - Trois niveaux
Cette architecture ajoute un serveur de traitement analytique en ligne (OLAP) à la conception à deux niveaux. Ce niveau intermédiaire fournit une vue abstraite de la base de données à l'utilisateur utilisateur et contribue à l'évolutivité et à la performance du système.
Dans chaque architecture d'entrepôt de données répertoriée, il est toujours possible d'apporter des optimisations supplémentaires, comme l'utilisation de clusters pour décentraliser la gestion et le traitement des données. Cela pourrait être utile pour relever les défis liés à la gouvernance données, au niveau local ou international. Les architectures d'entrepôt de données peuvent inclure des modèles en bus, en étoile et fédérés pour répondre à des besoins spécifiques.
Le diagramme suivant illustre une architecture d'entrepôt de données à trois niveaux. La structure de l'entrepôt de données peut être modifiée à chaque niveau pour s'adapter à d'autres composants similaires, par exemple en augmentant le nombre de datamarts pour support unités fonctionnelles supplémentaires dans l'organisation.
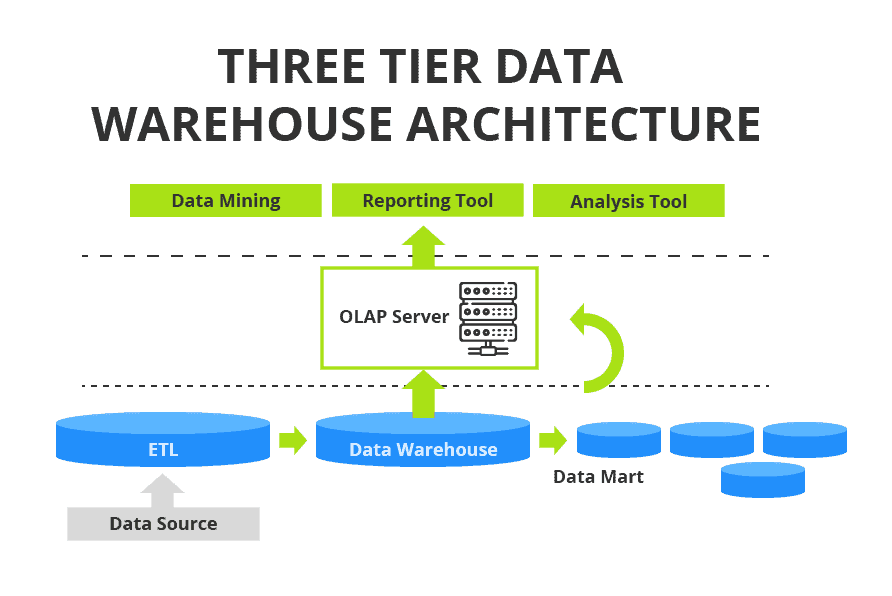
Diagramme de l'infrastructure de l'entrepôt de données
Les principaux éléments de l'architecture d'un entrepôt de données sont les suivants :
- Sources de données - bases de données et autres fichiers, y compris une base de données transactionnelle.
- L'entrepôt de données lui-même.
- Data Marts - pour des capacités analytiques spécifiques à la partie prenante .
- Serveur OLAP - permet une analyse rapide et flexible des données multidimensionnelles.
- Outils utilisés par partie prenante pour accéder aux analyses (applications).
L'une des valeurs de l'architecture dans l'entreposage de données est la simplicité. Une organisation peut commencer par une structure de base utilisant peu de composants et en ajouter d'autres ultérieurement dans différentes parties de l'architecture au fur et à mesure de l'évolution de la stratégie de données. En fait, il s'agit de conserver la structure de conception et d'étendre les éléments spécifiques, tels que les sources de données, pour donner de la profondeur et de l'ampleur à la solution.
Propriétés des architectures d'entrepôts de données
Les architectures d'entrepôt de données doivent se concentrer sur le traitement analytique. Le traitement transactionnel doit être effectué séparément, à l'aide d'une autre base de données. Une base de données de traitement transactionnel doit être une source de données pour l'entrepôt de données plus étendu.
Les autres caractéristiques de l'entrepôt de données doivent être les suivantes
- La capacité d'adapter rapidement l'utilisation des données à des fins d'analyse. Il peut s'agir d'un facteur essentiel pour la prévalence des analyses dérivées intégrant les données les plus récentes pour les décisions spécifiques qui doivent être prises.
- L'architecture doit support facilement support données supplémentaires sans avoir à repenser l'ensemble du système.
- Les données doivent être sécurisées de manière adéquate. L'entrepôt de données contient des données sur l'ensemble de l'organisation. Toute compromission à ce niveau est risquée et peut s'avérer très coûteuse.
- Les outils d'extraction, de transformation et de chargement doivent support différentes sources de données.
- La gestion de l'architecture ne doit pas être trop compliquée et doit être simplifiée pour faciliter l'utilisation et améliorer les résultats analytiques.
- L'architecture de l'entrepôt de données en exploration de données doivent utiliser des données fiables qui ont été correctement extraites, transformées et chargées dans l'entrepôt de données. Les outils d'exploration de données qui ne disposent pas de bonnes données ne donneront que des résultats inexacts.
- Au fur et à mesure que l'organisation mûrit et comprend comment utiliser les données, la solution d'entrepôt de données doit être capable de se transformer rapidement pour s'adapter aux changements.
Les architectures d'entrepôt de données devraient également offrir un niveau de garantie concernant la disponibilité, la sécurité, la capacité et la continuité de l'utilisation. Ces éléments de garantie de service pour l'entrepôt de données devraient également inclure la simplicité d'utilisation et la performance.
L'entrepôt de données doit facilement support outils et des applications tels que les rapports, l'exploration de données et les outils de développement d'applications.
Entrepôts de données traditionnels et entrepôts de données en nuage
Comme nous l'avons mentionné, un entrepôt de données est une collection de données provenant de diverses sources, réconciliées pour former un entrepôt de données plus étendu en vue d'un traitement analytique primaire destiné à support décisions de plusieurs parties prenantes au sein de l'organisation. La différence entre un entrepôt de entrepôt de données cloud traditionnel et un entrepôt de données cloud est liée à la puissance générale de l'utilisation de l'informatique en nuage.
Les entrepôts de données en nuage permettent à l'organisation de
- Profitez d'un stockage illimité, d'une élasticité rapide et d'une évolutivité.
- Améliorer la flexibilité pour prendre en charge différentes architectures.
- Améliorer la mobilité et l'accès aux données.
- Support analyse des données big data mieux que les solutions typiques sur site
- Déploiement plus rapide que les solutions sur site
- reprise après sinistreépreuve du feu.
- Mettre en commun les ressources informatiques de manière plus efficace.
Les organisations peuvent également faire preuve de créativité et utiliser une solution hybride tirant le meilleur des architectures sur site et en nuage pour support résultats de leur entrepôt de données pour les différentes parties prenantes.
Les solutions OLAP peuvent être exploitées pour l'une ou l'autre solution architecturale. L'OLAP permet une analyse multidimensionnelle des données, des informations et des connaissances de l'entrepôt de données afin de support modélisation complexe et l'analyse des tendances de la solution de l'entrepôt de données. L'OLAP permet une analyse rapide, efficace et réactive de l'informatique décisionnelle (BI) et de la prise de décision dans tous les domaines fonctionnels de l'organisation qui utilisent des entrepôts de données.
Le succès des solutions d'entrepôt de données repose sur la compréhension des besoins décisionnels de l'organisation. Chaque partie prenante doit être traitée différemment car la manière et le moment où elle prend des décisions varient. Dans la mesure du possible, permettez à l'utilisateur finallibre-service de modifier la configuration de l'accès aux données dans ses applications et la manière dont il y accède. Les parties prenantes devront donner leur avis sur le traitement ETL afin de s'assurer que les données sont compréhensibles et répondent à leurs besoins. Les parties prenantes et le support entrepôt de données doivent travailler ensemble de manière collaborative et coordonnée pour gérer, faire évoluer et transformer les données et l'entrepôt de données en une solution efficace, efficiente et économique pour l'organisation.


