
L'architecture de la plateforme de données est la structure fondamentale qui prend en charge la collecte, le stockage, le traitement et la gestion des données au sein d'une organisation. Les architectures de données évolutif sont conçues pour traiter efficacement des quantités massives de données, garantissant ainsi un fonctionnement harmonieux à mesure que le volume de données, la complexité et le besoin d'une plus grande démocratisation augmentent.
La mise en place d'uneplateforme de données évolutif est essentielle pour soutenir la croissance à long terme de toute entreprise. Au fur et à mesure que les entreprises se développent, le volume de données qu'elles doivent traiter, analyser et stocker augmente. Sans une architecture de plateforme de données évolutif , les entreprises sont confrontées à des goulets d'étranglement, à des inefficacités et à des coûts accrus. En fait, bon nombre des plus grandes entreprises actuelles - dont Netflix, Amazon et LinkedIn - ont bâti leur succès sur des plateformes données hautement évolutif, résilientes et efficaces.
Cet article présente les éléments essentiels d'une architecture de plateforme de données évolutif et réussie. Du choix de la bonne stratégie de mise à l'échelle à l'optimisation des flux de données, il propose des mesures concrètes pour garantir que la plateforme de données d'une organisation réponde à ses besoins actuels et à sa croissance future.
L'importance des architectures de données évolutif
Le paysage numérique évolue rapidement et les entreprises de tous les secteurs génèrent quotidiennement de grandes quantités de données. Qu'il s'agisse de données sur les clients dans le commerce de détail, de dossiers de patients dans le secteur de la santé ou de transactions financières dans le secteur bancaire, le volume d'informations à traiter et à stocker ne cesse de croître. Une plateforme de données évolutif garantit que les entreprises peuvent répondre aux demandes actuelles et aux défis de demain sans limites de système.
évolutivité est cruciale car les entreprises adoptent de nouvelles technologies telles que l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'analytique avancée - qui nécessitent toutes de grandes quantités de données pour fonctionner efficacement. La capacité à traiter efficacement des volumes de données croissants permet aux organisations de rester agiles et compétitives dans un monde axé sur les données.
Impliquer les parties prenantes dans le processus de conception
La mise en place d'une architecture de plateforme de données efficace nécessite une collaboration entre différents services. L'implication des principales parties prenantes dès le départ garantit que l'architecture s'aligne sur les objectifs de l'entreprise et répond aux besoins spécifiques des différentes équipes.
- Équipes informatiques : Veiller à ce que la plate-forme de données soit techniquement solide et réponde aux exigences d'évolutivité .
- Analystes commerciaux : Fournir des informations sur la manière dont les données seront utilisées pour la prise de décision, en veillant à ce que l'architecture prenne en charge l'analyse des données.
- Équipes de sécurité : Établir des protocoles pour protéger les informations sensibles et assurer la conformité avec les réglementations en matière de protection des données.
Un engagement précoce avec ces parties prenantes permet d'identifier les défis potentiels et de s'assurer que la plateforme répond aux exigences techniques et commerciales.
Construire des pipelines de données efficaces pour l'évolutivité
Au cœur de toute plateforme de données évolutif se trouve le pipeline de données - le système qui gère le flux de données depuis l'ingestion jusqu'à la transformation et au stockage. Un pipeline efficace garantit que les données se déplacent de manière transparente dans le système, quel que soit leur volume.
Construire un pipeline efficace :
- Automatiser l'ingestion de données: Configurez l'ingestion de données automatique ingestion de données à partir de sources multiples, y compris les bases de données, les API et les données streaming en temps réel.
- Transformation et nettoyage des données : Nettoyer et normaliser les données entrantes pour assurer la cohérence et la simplicité d'utilisation. L'automatisation de ces processus réduit les interventions manuelles et améliore l'évolutivité.
- Optimisation du stockage des données : Stockez les données dans des formats optimisés pour les cas d'utilisation, que ce soit dans une architecture de données en nuage ou dans des solutions de stockage de données sur site évolutif .
Un pipeline de données bien conçu garantit qu'une plateforme de données évolutif peut gérer des charges de travail croissantes tout en maintenant les performances et la fiabilité.
Mise à l'échelle horizontale ou verticale
Lors de la conception d'une architecture de base de données évolutif , il est essentiel de comprendre deux méthodes fondamentales de mise à l'échelle : la mise à l'échelle horizontale et la mise à l'échelle verticale. Ces stratégies offrent des approches différentes pour augmenter la capacité et les performances du système.
Mise à l'échelle horizontale
Il s'agit d'ajouter des serveurs (ou nœuds) à un système, ce qui permet de répartir la charge de travail sur plusieurs machines. Au fur et à mesure que les données augmentent, de nouveaux serveurs peuvent être ajoutés de manière transparente pour gérer la demande accrue. Cette méthode est couramment utilisée dans les architectures basées sur l'informatique en nuage, car elle permet une mise à l'échelle presque illimitée.
Avantages :
- Facile à mettre en œuvre dans les environnements en nuage.
- Permet une évolutivité quasi infinie.
- Réduit le risque de points de défaillance uniques.
Mise à l'échelle verticale
La mise à l'échelle verticale augmente la puissance de l'infrastructure existante en mettant à niveau les composants matériels, par exemple en ajoutant plus de processeur, de mémoire vive ou de stockage à un seul serveur. Bien qu'elle soit efficace pour des charges de travail spécifiques, la mise à l'échelle verticale a des limites, car il n'y a pas de limite à ce qui peut être mis à niveau avant d'atteindre un plafond.
Avantages :
- Simple à mettre en œuvre pour les petits systèmes.
- Il n'est pas nécessaire de modifier les applications de manière significative.
- Idéal pour les charges de travail qui nécessitent une puissance de traitement importante sur chaque nœud.
Le choix entre la mise à l'échelle horizontale et la mise à l'échelle verticale dépend des besoins de l'organisation. Toutefois, pour la plupart des plateformes données d'entreprise, la mise à l'échelle horizontale est privilégiée pour sa flexibilité et son évolutivité à long terme.
Optimisation avec le partitionnement, le partage et la redondance des données
Une fois qu'une organisation a choisi une approche de mise à l'échelle, le partitionnement des données, le partage et la redondance deviennent essentiels pour optimiser les performances.
- Partitionnement des données : Le partitionnement divise les grands ensembles de données en morceaux plus petits et plus faciles à gérer, généralement basés sur des groupements logiques tels que des plages de dates ou des régions. Cela améliore les performances des requête et permet une récupération des données plus rapide récupération des données en limitant l'étendue des recherches.
- La répartition (Sharding) : Le sharding va plus loin en répartissant les données sur plusieurs serveurs. Chaque parcelle est une base de données indépendante qui contient un sous-ensemble de données, ce qui permet d'améliorer le traitement et le stockage des données évolutif . Cette technique est essentielle pour les applications à fort trafic, car elle permet d'équilibrer les charges sur plusieurs serveurs.
- Redondance et réplication des données : Pour garantir la disponibilité des données et la tolérance aux pannes, la redondance des données réplique les informations sur plusieurs serveurs ou sites. Si un serveur tombe en panne, les systèmes redondants garantissent que les données restent accessibles, évitant ainsi les interruptions de service.
En tirant parti du partitionnement, du partage et de la redondance, les entreprises peuvent créer des architectures de données évolutif qui maintiennent des performances élevées même lorsque le volume de données augmente.
Exploiter les services en nuage et les solutions hybrides
Alors que les entreprises s'orientent vers une plus grande transformation numérique, l'architecture de données en nuage est devenue un outil essentiel pour l'évolutivité. Les services cloud offrent des ressources à la demande qui peuvent s'ajuster automatiquement pour répondre aux besoins d'une plateforme au fur et à mesure que les données augmentent.
- Hyperscalers basés sur le cloud : Les plateformes en nuage telles que AWS, Microsoft Azure, Actian DataConnect et Google Cloud offrent des fonctions de mise à l'échelle automatique qui ajustent la puissance de calcul et le stockage évolutif des données en fonction du trafic et des volumes de données. Cela élimine le besoin d'efforts manuels de mise à l'échelle et garantit que la plateforme peut gérer les fluctuations de la demande.
- Solutions hybrides : Les architectures de données hybrides permettent une intégration transparente pour les entreprises qui ont besoin d'une combinaison d'infrastructures sur site et en nuage. Les données peuvent être stockées localement pour des raisons de conformité ou de sécurité, tout en tirant parti de l'évolutivité de l'informatique en nuage pour la puissance de traitement.
Les solutions en nuage offrent un moyen efficace de créer et de maintenir une plateforme de données évolutif sans investissement initial important dans l'infrastructure.
Garantir la performance et la disponibilité avec l'équilibrage de charge
Pour maintenir des performances optimales, l'équilibrage de charge est crucial. Les équilibreurs de charge répartissent le trafic réseau entrant sur plusieurs serveurs afin de garantir qu'aucun serveur n'est submergé, ce qui évite les goulets d'étranglement et améliore la disponibilité de la plate-forme de données.
- équilibrage de charge dynamique : Les équilibreurs de charge modernes utilisent des algorithmes pour évaluer la charge actuelle du serveur et diriger le trafic en conséquence. Cela évite de solliciter le système et garantit des performances constantes.
- Protection contre le basculement : En cas de défaillance d'un serveur, les répartiteurs de charge peuvent automatiquement réacheminer le trafic vers les serveurs en état de marche, ce qui minimise les interruptions.
L'intégration de l'équilibrage de charge dans l'architecture de votre base de données évolutif garantit que les performances restent stables lorsque la demande augmente.
Exemples d'architecture de plate-forme de données évolutif
Comprendre comment les entreprises performantes conçoivent leurs architectures de plateformes de données évolutif peut fournir des informations précieuses. Vous trouverez ci-dessous des exemples concrets d'architectures utilisées par des entreprises telles que Netflix et Amazon, qui montrent comment elles tirent parti de l'évolutivité pour gérer des volumes de données considérables.
1. L'évolutif architecture microservices de Netflix
Netflix est connu pour son architecture basée sur les microservices, qui décompose les grandes applications en processus plus petits et indépendants. Cela permet à Netflix de faire évoluer les différentes parties de sa plateforme en fonction des besoins, comme l'authentification de l utilisateur , le streaming vidéo ou les moteurs de recommandation de contenu. Chaque microservice peut être déployé indépendamment et mis à l'échelle horizontalement.
Voici un modèle simplifié de l'architecture de Netflix :

Cette architecture permet à Netflix d'adapter des services spécifiques en fonction de la à la demande, garantissant ainsi un service ininterrompu même en cas de pic d'utilisation.
2. L'architecture du commerce électronique d'Amazon
L'architecture évolutif de la base de données d'Amazon prend en charge sa vaste plateforme de commerce électronique, qui traite des millions de transactions par jour. Amazon utilise une combinaison d'échelonnement horizontal, de partitionnement des données et de partage pour gérer efficacement son inventaire, les commandes de ses clients et sa logistique.
Voici une représentation de l'architecture d'Amazon :

Cette architecture permet à Amazon de gérer les charges de travail importantes et dynamiques de sa plateforme de commerce électronique en répartissant les tâches sur de nombreuses bases de données plus petites.
3. L'architecture de traitement des données en temps réel de LinkedIn
L'architecture de LinkedIn est conçue pour gérer l'ingestion de données à grande échelle et le traitement en en temps réel réel, en veillant à ce que les membres reçoivent instantanément les mises à jour (telles que les messages du fil d'actualité et les recommandations d'emploi). LinkedIn utilise Apache Kafka pour le streaming données en temps réel et Hadoop pour le stockage des données distribuées.
Voici comment LinkedIn structure l'architecture de sa plateforme de données :
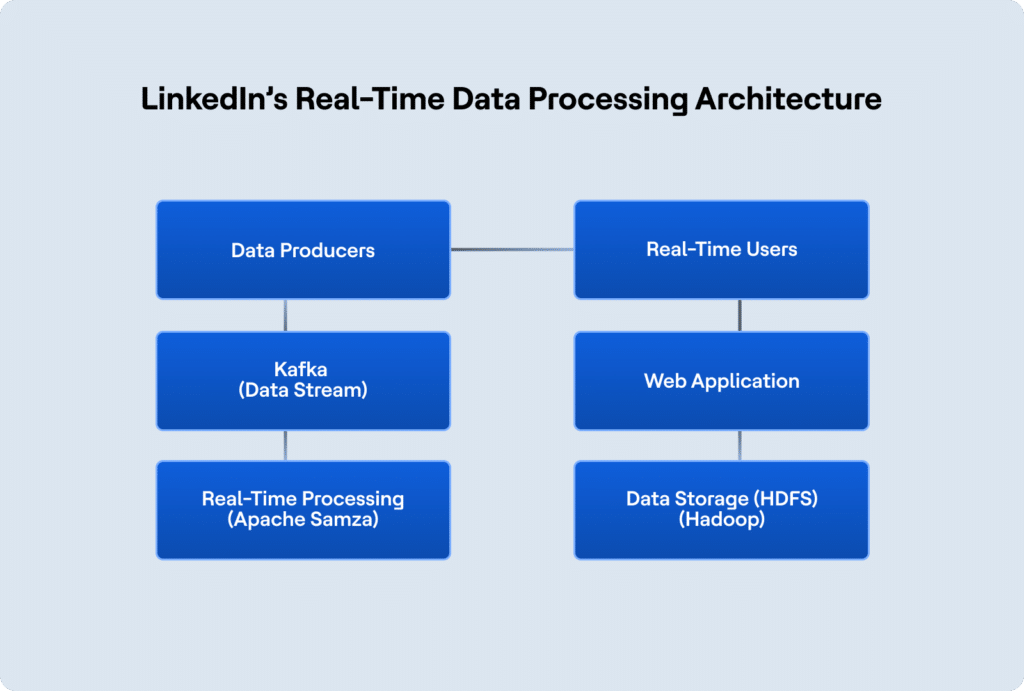
Cette architecture permet à LinkedIn de traiter des données en temps réel tout en garantissant que la plateforme peut s'adapter au nombre croissant d'utilisateurs et de fonctionnalités.
plateforme de données Actian
Pour les organisations qui recherchent une solution prête à l'emploi pour construire une plateforme de données évolutif , la plateforme de données Actian constitue une base solide. Actian offre une plateforme de gestion des données pour l'intégration, le stockage et le traitement, conçue pour l'évolutivité.
- évolutif Intégration des données : Les capacités d'intégration d'Actian garantissent que les données provenant de diverses sources circulent de manière transparente dans la plateforme, ce qui facilite la gestion des volumes de données croissants.
- Intégration avec Zeenea : Actian peut travailler avec la plateforme de découverte de données Zeenea, ce qui permet aux entreprises d'améliorer la gouvernance leurs données et d'en assurer la qualité au fur et à mesure qu'elles évoluent. Ce partenariat soutient la croissance évolutif en offrant une solution complète de découverte de données et de gestion.
- Traitement parallèle : Avec Actian DataFlow, le traitement parallèle des opérations d'extraction, de transformation et de chargement (ETL) peut être effectué pour réduire les goulots d'étranglement lorsque les données se déplacent dans le pipeline. Il permet également une analyse en temps réel qui aide les entreprises à agir plus rapidement sur les données.
En tirant parti de la plateforme de données Actian, les entreprises peuvent se concentrer sur l'expansion de leurs activités sans avoir à se préoccuper de la mise en place d'une infrastructure à partir de zéro.
La mise en place d'une architecture de plateforme de données évolutif est essentielle pour les entreprises qui cherchent à gérer les demandes croissantes en matière de données. Qu'il s'agisse d'une mise à l'échelle horizontale, d'un partitionnement des données ou de l'exploitation de services en nuage, les bonnes stratégies peuvent garantir que votre plateforme reste robuste, flexible et prête pour la croissance future. L'engagement des intervenants, l'optimisation des pipelines de données et l'utilisation de solutions comme la plateforme de données Actian sont des étapes cruciales dans la création d'un système de données qui favorise la réussite de l'entreprise.

