Comment Actian Vector vous aide à éliminer les cubes OLAP
Actian Corporation
16 avril 2018
Les cubes OLAPtraitement analytique en ligne) sont largement utilisés aujourd'hui parce que de nombreuses plateformes base de données ne peuvent pas analyser rapidement de grands volumes de données. En effet, la plupart des logiciels de base de données n'exploitent pas pleinement la puissance de calcul et la mémoire pour offrir des performances optimales. Voici quelques-uns des symptômes de cette situation :
- Les requêtes volumineuses finissent par accaparer les ressources du serveur.
- La réponse devient plus lente lorsque la taille des données et le nombre d'utilisateurs augmentent.
- La prise en charge de requêtes simultanées devient difficile, voire impossible.
- Les tables agrégées/matérialisées supplémentaires, les indices et parfois même les data marts individuels n'offrent pas la performance et la simultanéité requises.
Les magasins cube OLAP ont été créés pour répondre au besoin d'un utilisateurBI d'agréger, de couper et de découper rapidement de grandes quantités de données pour un ensemble de questions prédéterminées. Nous allons maintenant voir comment nous pouvons utiliser Actian Vectornotre base de données analytique en colonnes à haute vitesse, pour éliminer l'utilisation des cubes OLAP.
Quels sont les inconvénients de l'utilisation de cube OLAP Stores ?
- Investissement supplémentaire dans le matériel/logiciel et coûts de maintenance continus.
- Des compétences entièrement nouvelles en expressions multidimensionnelles (MDX) sont nécessaires pour requête cubes OLAP.
- impose un schéma strict (en étoile ou en flocon de neige), alors que certains magasins Cube de dernière génération support tables 3NF (ou les modèles ROLAP). Mais les meilleures performances sont toujours obtenues avec un schéma en étoile.
- Ils limitent la liberté des requête ad hoc. La conception du cube OLAP doit faire l'objet d'une réflexion approfondie. Une fois qu'il est construit, seules les lignes et les colonnes incluses seront disponibles pour les requêtes. Souvent, un nouveau cube est nécessaire pour chaque nouvelle requête.
- Ajoute un temps de traitement important et crée de nouveaux goulets d'étranglement dans le cycle de vie de la BI. L'utilisateur BI devrait payer cher en perte de temps si le cube OLAP était construit de manière incorrecte. La fraîcheur des données est compromise car les données doivent passer des systèmes opérationnels à l'entrepôt de données, puis au cube OLAP et enfin à outils bi.
Regarder sous le capot
Examinons ce à quoi vous renoncez avec un cube OLAP. Voici un exemple simple où les données brutes de la base de données relationnelle sous-jacente se présentent comme suit :
| Vente _date | Année | mois | décennie | ville _id | ville _nom | État | Région _id | Région _nom | Produit _id | Nom du produit | Ventes _Montant |
| 1/1/1990 | 1990 | Janvier | 1990-2000 | 1 | Palo alto | CA | 1 | États-Unis - Ouest | 1 | Boulons | 20 |
| 1/2/1990 | 1990 | Janvier | 1990-2000 | 1 | Palo alto | CA | 1 | États-Unis - Ouest | 1 | Boulons | 23 |
| 1/3/1990 | 1990 | Janvier | 1990-2000 | 1 | Palo alto | CA | 1 | États-Unis - Ouest | 1 | Boulons | 15 |
| 1/1/1993 | 1993 | Janvier | 1990-2000 | 1 | Palo alto | CA | 1 | États-Unis - Ouest | 2 | marteau | 14 |
| 5/1/1993 | 1994 | Mai | 1990-2000 | 2 | La Jolla | CA | 2 | États-Unis - Ouest | 3 | vis | 60 |
| 1/1/2003 | 2003 | Janvier | 2000-2010 | 3 | Dallas | TX | 1 | États-Unis - Sud | 1 | Boulons | 12 |
| 5/1/1993 | 1993 | Mai | 2000-2010 | 4 | Atlanta | GA | 2 | États-Unis - Sud | 3 | Vis | 34 |
| 10/1/2004 | 2004 | Octobre | 2000-2010 | 5 | New York (en anglais) | NY | 1 | États-Unis - Est | 1 | Boulons | 35 |
| 10/2/2004 | 2004 | Novembre | 2000-2010 | 6 | Boston | MA | 1 | États-Unis - Est | 1 | Boulons | 37 |
| 10/3/2004 | 2004 | Décembre | 2000-2010 | 1 | Palo Alto | CA | 1 | États-Unis - Ouest | 1 | Boulons | 39 |
| 10/4/2004 | 2004 | Janvier | 2000-2010 | 1 | Palo Alto | CA | 1 | États-Unis - Ouest | 1 | Boulons | 42 |
| 10/5/2004 | 2004 | Février | 2000-2010 | 7 | Madison | WI | 1 | Centre des États-Unis | 1 | Boulons | 44 |
| 10/6/2004 | 2004 | Mars | 2000-2010 | 8 | Chicago (en anglais) | IL | 1 | Centre des États-Unis | 2 | marteau | 46 |
| 4/1/2011 | 2011 | Avril | 2010-2020 | 9 | Salt Lake City | UT | 2 | États-Unis - Ouest | 3 | vis | 49 |
| 5/2/2012 | 2012 | Mai | 2010-2020 | 1 | Palo Alto | CA | 2 | États-Unis - Ouest | 1 | Boulons | 51 |
| 6/3/2013 | 2013 | Juin | 2010-2020 | 2 | La Jolla | CA | 2 | États-Unis - Ouest | 3 | Vis | 53 |
| 7/4/2014 | 2014 | Juillet | 2010-2020 | 10 | Jersey City | NJ | 2 | États-Unis - Est | 1 | Boulons | 56 |
Si un utilisateur souhaite créer un simple cube OLAP pour les ventes à partir des données ci-dessus et des métriques d'intérêt agrégées sales_amounts pour chaque décennie, année, par produit et région, le cube OLAP contiendrait les données suivantes :
| Décennie | Année | Nom de la région | Nom du produit | Chiffre d'affaires | Prix moyen |
| 1990-2000 | 1994 | États-Unis - Ouest | Vis | $60.00 | $19.33 |
| 1990-2000 | 1993 | États-Unis - Sud | Vis | $34.00 | $14.00 |
| 1990-2000 | 2003 | États-Unis - Sud | Boulons | $12.00 | $60.00 |
| 2000-2010 | 2004 | Centre des États-Unis | Boulons | $44.00 | $34.00 |
| 2000-2010 | 2004 | Centre des États-Unis | Marteau | $46.00 | $12.00 |
| 2000-2010 | 2004 | États-Unis - Est | Boulons | $72.00 | $44.00 |
| 2000-2010 | 2004 | États-Unis - Ouest | Boulons | $81.00 | $46.00 |
| 2000-2010 | 2011 | États-Unis - Ouest | Vis | $49.00 | $36.00 |
| 2010-2020 | 2012 | États-Unis - Ouest | Boulons | $51.00 | $40.50 |
| 2010-2020 | 2013 | États-Unis - Ouest | vis | $53.00 | $49.00 |
| 2010-2020 | 2014 | États-Unis - Est | Boulons | $56.00 | $51.00 |
| 2010-2020 | 1994 | États-Unis - Ouest | Vis | $60.00 | $53.00 |
Les données sont agrégées par décennie, année, nom_de_région, nom_de_produit. Le niveau de détail transactionnel est perdu. C'est la raison pour laquelle certains des magasins cube OLAP les plus évolués proposent une fonction d'exploration permettant à l'utilisateur consulter les données détaillées. Cependant, les performances peuvent se dégrader si la quantité de données derrière l'agrégation est importante.
Une requête MDX typique pour obtenir ces données à partir du cube ressemblerait à ceci, en fonction de ce que l'utilisateur souhaite voir sur les lignes, les colonnes et les points de données.
AVEC
MEMBER[mesures].[prix moyen] AS
'[mesures].[montant_des_ventes] / [mesures].[nombre_de_ventes]
SELECT
{[mesures].[sales_sum],[mesures].[avg price]} ON COLUMNS,
{[produit].membres, [année].membres} ON ROWS
FROM SALES_CUBE
Le prix moyen est une mesure calculée. Notez que les mesures calculées peuvent être spécifiées dans la définition cube OLAP ou dans la requête MDX. L'un des avantages des mesures calculées définies dans les cubes OLAP est que si la requête est modifiée pour contenir un filtre ou si une dimension supplémentaire est ajoutée, la mesure calculée est automatiquement recalculée avec les nouveaux paramètres.
Ainsi, le cube OLAP finit par être une solution partielle à un problème : les bases de données relationnelles orientées lignes ne sont tout simplement pas assez rapides pour les requêtes analytiques. Que demanderaient vos utilisateurs OLAP s'ils pouvaient avoir tout ce qu'ils veulent ? Les utilisateurs nous font part des exigences suivantes :
- Vitesse comparable à celle de l'OLAP, voire supérieure, avecsupport complètesupport requête ad hoc
- La possibilité d'utiliser le modèle de données de son choix
- Tous leurs outils bi préférés outils bi
- Les données les plus récentes disponibles
- Accès à des données détaillées complètes dans la même requête, sans perte de performance
Cela semble impossible ? Ce n'est pas le cas. Actian Vector peut vous offrir tout cela et bien plus encore. Comment cela est-il possible ? Lisez la suite !
Remplacer les cubes OLAP par des cubes vectoriels
Actian Vector est particulièrement bien placé pour remplacer les cubes OLAP. Nous l'avons conçu dès le départ avec un certain nombre d'optimisations pour augmenter considérablement la performance des requêtes analytiques. Voici un résumé rapide de ce que nous avons construit :
- Traitement vectoriel: La vectorisation fait passer la parallélisation au niveau supérieur en envoyant une seule instruction à plusieurs points de données, ce qui permet d'obtenir une réponse en temps quasi réel.
- stockage en colonnes: Columnar réduit considérablement les entrées-sorties en ne chargeant en mémoire que les colonnes requises dans une requête , au lieu de charger toutes les colonnes en mémoire et de sélectionner ensuite les colonnes requises pour répondre à la requête.
- Optimisation de in-memory: L'utilisation avancée de la mémoire cache du processeur et de la mémoire principale, ainsi que la compression et la décompression in-memory accélèrent le processus.
- Flexibilité: Vector fonctionne avec n'importe quel modèle de données - étoile, flocon de neige, 3NF et dé-normalisé - éliminant ainsi le besoin de créer n'importe quel type de matérialisation des données. Puisque l'utilisateur BI travaille à partir de la source de données, la liberté de requête n'est pas perdue.
- Richesse fonctionnelle: Les fonctions OLAP/Windows avancées permettent à l'utilisateur de poser un large éventail de questions sophistiquées.
Passer des cubes au vecteur actien
Pour migrer des rapports BI à partir de cubes OLAP, il est important de comprendre les caractéristiques du cube qui doivent être migrées. Il s'agit notamment des éléments suivants
- Modèle cube OLAP du cube - Comprendre le modèle de données du cube lui-même et le mettre en correspondance avec le modèle de données du SGBDR .
- Les requêtes MDX, les mesures calculées et les filtres utilisés.
- KPIs - Key Performance Indicators (indicateurs clés de performance).
- Analyse d'hypothèses pour différents scénarios.
cube OLAP Modèle cube OLAP
Examinez le cube OLAP et identifiez le type de modèle de données sur lequel il repose : ROLAP, HOLAP ou MOLAP. Les modèles ROLAP reposent sur des modèles de données de troisième forme normale (3NF) dans lesquels les données sont fortement normalisées. En général, l'utilisation de modèles ROLAP dans les cubes entraîne une baisse des performances.
HOLAP est un modèle hybride qui utilise une combinaison de modèles en étoile ou en flocon de neige, dé-normalisés et 3NF. Ce modèle présente également des inconvénients en termes de performances.
MOLAP est le modèle sous-jacent le plus souhaité lorsqu'un modèle de données en étoile ou en flocon de neige est utilisé et offre les meilleures performances. Généralement, dans un cycle de vie BI, les données sources sont en 3NF et doivent passer par un long processus de transformation pour être converties en un modèle de schéma en étoile . La pénalité est payée d'avance pour obtenir de meilleures performances plus tard.
Les facteurs suivants doivent être examinés si une requête est utilisée à la source des données :
- Dimensions : Comment cela se passe-t-il dans le cube ? Spécialement pour les modèles ROLAP et HOLAP.
- Mesures : Mesures calculées et mesures normales.
- Faits : S'agit-il d'un seul tableau ou d'une combinaison de tableaux ?
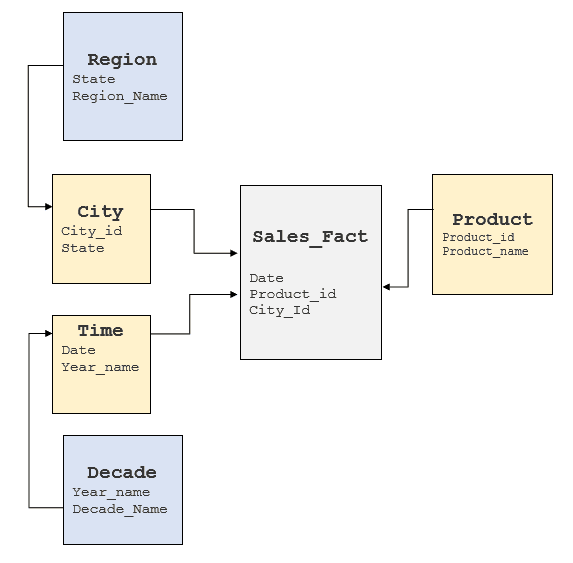
Il est important d'examiner les facteurs ci-dessus pour comprendre le modèle SGBDR sous-jacent et voir où ces éléments peuvent être obtenus. En règle générale, les entrepôts de données sont dotés de modèles en étoile ou en flocon de neige, mais certains entrepôts de données ont tendance à avoir un modèle fortement normalisé. Pour le cube ci-dessus, un modèle en flocon de neige typique ressemblerait à ce qui suit :
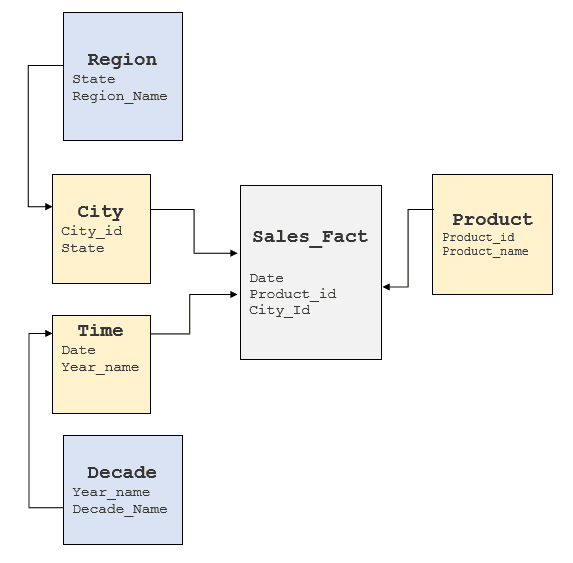
Conversion des requêtes MDX en SQL
Examinez la requête MDX et identifiez les éléments suivants à partir du cube OLAP et de la requête MDX. Reportez-vous à un didacticiel MDX de base si nécessaire. Voici ce que vous devez savoir :
- Dimensions
- Mesures
- Mesures calculées
- Tranches de données ou Filtres (Exemple : Si l'utilisateur veut connaître les ventes pour les seuls "boulons" ou seulement pour le mois de janvier).
Prenons l'exemple de la requête MDX de la section précédente :
AVEC
MEMBER[mesures].[prix moyen] AS
'[mesures].[montant_des_ventes] / [mesures].[nombre_de_ventes]
SELECT
{[mesures].[sales_sum],[mesures].[avg price]} ON COLUMNS,
{[produit].membres, [année].membres} ON ROWS
FROM SALES_CUBE
Où ?
- Le prix moyen est une mesure calculée
- Sales_amt est une mesure définie dans le cube
- [produit].membres est la dimension du produit
- [Année].membres est l'année Dimension
Vous souhaitez maintenant convertir les requêtes MDX en requêtes SQL sur la base du modèle ci-dessus. La requête MDX peut être réécrite en SQL comme suit :
Select nom_année, nom_produit, somme(montant_des_ventes) en tant que chiffre d'affaires, moyenne(montant_des_ventes) en tant que moyenne_des_ventes from Ventes FT join Time_Dimension TD on FT.date = TD.date join Month_Dimension MD on month(TD.date) = MD.month join Year_Dimension YD sur year(date) = YD.year join City_Dimension RD sur FT.city_id = RD.city_id join State_Dimension SD sur FT.state_id= RD.state_id join Product PD on FT.product_id = PD.Product_id group by year_name, product_name
ou simplifier encore plus la requête en supprimant les tableaux de dimensions s'ils n'ont été introduits que pour construire le cube :
Sélectionner date_partie(année, date_vente) comme nom_année, nom_produit, sum(montant_des_ventes) comme chiffre d'affaires , avg(montant_des_ventes). comme chiffre_des_ventes from Ventes FT join Product PD on FT.product_id = PD.Product_id group by decade,year_name, region_name, product_name
Remarque : il n'est pas sous-entendu que les jointures avec d'autres tables peuvent être complètement éliminées. Seules les tables qui ont été introduites simplement pour respecter le schéma strict étoile/flocon de neige peuvent être éliminées.
Si l'outil de BI ne fournit pas de fonctions analytiques de fenêtre, il faut se référer aux fonctions analytiques et aux fonctions de fenêtre fournies par Vector pour qu'elles puissent être exécutées dans la base de données.
Si l'utilisateur souhaite explorer un ensemble spécifique de lignes, l'agrégation peut être supprimée et la requête peut être exécutée dans la base de données. Par exemple, si l'utilisateur souhaite obtenir les chiffres de vente de janvier 1993 pour le produit Boulons, il peut utiliser la requête SQL suivante :
Sélectionner Date_part(année, date_vente) comme nom_année, nom_du_produit, montant_des_ventes comme ventes from Ventes FT join Product PD on FT.product_id = PD.Product_id où Nom_du_produit = "Boulons" et Date_part(year, sale_date) = "1993" et Date_part(month, sale_date) = "January"
Indicateurs clés de performance
Dans la terminologie commerciale, un indicateur clé de performance (ICP) est une mesure quantifiable permettant d'évaluer la réussite d'une entreprise.
Un objet ICP simple se compose d'informations de base, de l'objectif, de la valeur réelle atteinte, d'une valeur d'état, d'une valeur de tendance et d'un dossier dans lequel l'ICP est visualisé. Les informations de base comprennent le nom et la description de l'ICP. Dans un cube Microsoft SQL Server Analysis Services, l'objectif est une expression MDX qui s'évalue à un nombre. La valeur réelle est une expression MDX qui évalue un nombre. Les valeurs d'état et de tendance sont des expressions MDX qui évaluent un nombre. Le dossier est un emplacement suggéré pour l'ICP à présenter au client.
Bien que certains cube OLAP fournissent des interfaces élégantes et faciles à utiliser pour stocker et mettre en œuvre des indicateurs de performance clés et des actions, ceux-ci peuvent facilement être mis en œuvre en utilisant une combinaison de fonctions de base de données plus courantes et de code d'application.
Analyse d'hypothèses pour différents scénarios
Des capacités d'analyse par simulation sont fournies par certains magasins de cubes avec des interfaces faciles à utiliser. Ces fonctions peuvent également être mises en œuvre en utilisant les fonctionnalités de la base de données et le code de l'application, moyennant quelques efforts.
Ce type d'analyse nécessite le stockage de différents scénarios et l'analyse de l'impact de la situation actuelle de l'entreprise par rapport à ces différents scénarios. Ce type d'analyse est couramment utilisé dans les services financiers et les entreprises commerciales pour évaluer en permanence le risque et l'impact des transactions.
Une analyse détaillée des besoins serait nécessaire et sort un peu du cadre de cet article de blog.
Résumé
Pour les utilisateurs OLAP qui cherchent à simplifier le cycle de vie de la BI, la base de données analytiques Actian Vector offre une alternative viable aux cubes OLAP grâce à sa technologie révolutionnaire, ses performances supérieures et ses capacités analytiques dans la base de données. L'avantage la migration est la réduction des coûts et une meilleure expérience de l'utilisateur BI par le biais de la requête freedom.
Ne vous contentez pas de me croire sur parole. Essayez-le vous-même. Nous avons préparé un guide et une copie d'évaluation de Vector, ainsi que tous les supports dont vous aurez besoin pour tester Vector en une heure environ. Vous pouvez poser des questions à la communauté active de Vector ici.
S'abonner au blog d'Actian
Abonnez-vous au blogue d'Actian pour recevoir des renseignements sur les données directement à vous.
- Restez informé - Recevez les dernières informations sur l'analyse des données directement dans votre boîte de réception.
- Ne manquez jamais un article - Vous recevrez des mises à jour automatiques par courrier électronique pour vous avertir de la publication de nouveaux articles.
- Tout dépend de vous - Modifiez vos préférences de livraison en fonction de vos besoins.