Actian Vector for Hadoop pour une fonctionnalité SQL plus complète et des données actuelles
Actian Corporation
7 juin 2020

Dans cette deuxième partie d'une série de blogues en trois parties (partie 1), nous expliquerons comment l'exécution SQL dans Actian Vector in Hadoop (VectorH) est beaucoup plus fonctionnelle et prête à fonctionner dans un environnement opérationnel, et comment la capacité de VectorH à traiter efficacement les mises à jour de données peut permettre à votre environnement de production de demeurer à jour avec l'état de votre entreprise. Dans la première partie de cet article de blog en trois parties, nous avons montré l'énorme avantage en termes de performances que VectorH possède par rapport à d'autres alternatives SQL sur Hadoop. La troisième partie couvrira les avantages du format de fichier VectorH.
Une meilleure fonctionnalité SQL pour la productivité des entreprises
L'un des premiers obstacles à l'exploitation de Hadoop est la nécessité de disposer de compétences MapReduce, qui sont rares et coûteuses, et dont l'application à une question analytique donnée prend du temps. Ces défis ont conduit à l'émergence de nombreuses alternatives SQL sur Hadoop, dont beaucoup sont maintenant des projets dans l'écosystème Apache pour Hadoop. Si ces différents projets ouvrent l'accès aux millions d'utilisateurs professionnels qui savent déjà écrire des requêtes SQL, ils exigent souvent d'autres compromis : différences de syntaxe, limitations de certaines fonctions et extensions, technologie d'optimisation immature et implémentations inefficaces. Existe-t-il un meilleur moyen d'intégrer SQL à Hadoop ?
Oui ! Actian VectorH 6.0 supporte une implémentation beaucoup plus complète, avec un support ANSI SQL:2003 complet, ainsi que des extensions analytiques comme CUBE, ROLLUP, GROUPING SETS, et WINDOWING pour l'analytique avancée. Examinons la charge de travail que nous avons évaluée dans notre article SIGMOD, sur la base des 22 requêtes du benchmark TPC-H.
Chacune des autres solutions SQL sur Hadoop a rencontré des problèmes lors de l'exécution des requêtes SQL standard qui constituent le benchmark TPC-H, ce qui signifie que les utilisateurs professionnels qui connaissent le langage SQL peuvent être amenés à effectuer des modifications manuellement ou à subir des résultats médiocres, voire des requêtes qui échouent :
- Apache Hive 1.2.1 n'a pas pu terminer la requête numéro 5.
- Les performances de Cloudera Impala 2.3 sont entravées par les jointures et le traitement d'agrégation à cœur unique, ce qui crée des goulets d'étranglement pour l'exploitation des ressources de traitement parallèle.
- Apache Drill 1.5 n'a pas pu compléter la requête numéro 21, et seulement 9 des requêtes ont été exécutées sans modification de leur code SQL.
- Apache Spark SQL version 1.5.2 étant un sous-ensemble limité de ANSI SQL, la plupart des requêtes ont dû être réécrites en Spark SQL pour éviter les sous-requêtes IN/EXISTS/NOT EXISTS, et certaines requêtes ont nécessité une définition manuelle des ordres de jointure en Spark SQL. VectorH dispose d'un optimiseur de requête mature qui réorganise les jointures sur la base de métriques de coûts afin d'améliorer les performances et de réduire les besoins en bande passante d'entrée/sortie.
- La version 1.3.1 d'Apache Hawq est basée sur PostgreSQL, et ses fondations technologiques plus anciennes ne peuvent donc pas rivaliser avec les performances d'un moteur de requête vectorisé.
Des mises à jour efficaces pour une vision plus cohérente de l'entreprise
Un autre obstacle à l'adoption d'Hadoop est le fait qu'il s'agit d'un système de fichiers à appendices uniquement, ce qui limite la capacité du système de fichiers à gérer les insertions et les suppressions. Pourtant, de nombreuses applications commerciales nécessitent des mises à jour des données, ce qui impose au système de gestion de base de données de gérer ces changements. VectorH peut recevoir et appliquer des mises à jour à partir de sources de données transactionnelles pour s'assurer que les analyses sont effectuées sur la représentation la plus récente de votre entreprise, et non pas sur celle d'il y a une heure, ou d'hier, ou du dernier chargement de lot dans votre entrepôt de données.
- Dans le cadre de lacharge de travail charge de travail ad hoc d support décision qu'elle représente, PTC-H doit effectuer des insertions et des suppressions. Il existe deux flux de rafraîchissement qui effectuent des insertions et des suppressions dans les six tables de faits.
- Quatre des alternatives SQL on Hadoop ne support pas support mises à jour sur HDFS : Impala, Drill, SparkSQL et Hawq. Elles ne seraient pas en mesure de répondre aux exigences d'un résultat audité complet.
- Le cinquième, Hive, support mises à jour, mais les performances de l'exécution des requêtes après le traitement des mises à jour sont considérablement réduites.
- VectorH a exécuté les mises à jour plus rapidement que Hive. Grâce à ses arbres Delta positionnels en instance de brevet, VectorH suit les insertions et les suppressions séparément des blocs de données, maintenant une conformité ACID totale tout en préservant le même niveau de performance des requête (pas de pénalité !).
- Voici les données récapitulatives de nos tests qui montrent la pénalité de performance sur Hive alors qu'il n'y a pas d'impact sur VectorH lors de l'exécution des mises à jour (les données détaillées suivent) :
- Les insertions ont pris 36 % de temps en plus et les suppressions ont pris 796 % de temps en plus sur Hive par rapport à VectorH.
montre que les PDT n'ont pas de surcoût mesurable, alors que les performances de Hive sont pénalisées de 38 % :
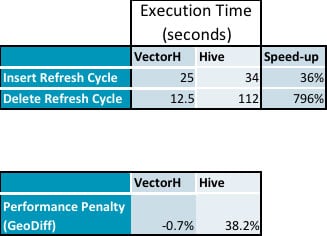
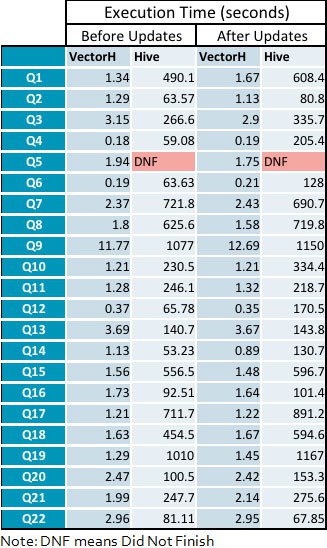
- La vitesse moyenne de VectorH par rapport à Hive passe de 229 fois avant les cycles d'actualisation à 331 fois après l'application des mises à jour, avec une fourchette de 23 à 1141 pour les requêtes individuelles.
Annexe : Délais d'exécution des requête détaillées
S'abonner au blog d'Actian
Abonnez-vous au blogue d'Actian pour recevoir des renseignements sur les données directement à vous.
- Restez informé - Recevez les dernières informations sur l'analyse des données directement dans votre boîte de réception.
- Ne manquez jamais un article - Vous recevrez des mises à jour automatiques par courrier électronique pour vous avertir de la publication de nouveaux articles.
- Tout dépend de vous - Modifiez vos préférences de livraison en fonction de vos besoins.