Actian présente de gros avantages par rapport à SQL sur les alternatives Hadoop
Actian Corporation
6 juin 2020

Imaginez que les rapports qui prennent actuellement plusieurs minutes à exécuter dans Hadoop puissent donner des résultats en quelques secondes. Obtenez des réponses à des questions détaillées sur les chiffres de vente et les tendances des clients en temps réel. Faire des prévisions de chiffre d'affaires sur la base d'indicateurs clients actualisés à partir d'un large éventail de sources. Réaliser des itérations plus rapides en simulant différentes décisions commerciales afin d'obtenir de meilleurs résultats. La plateforme d'analyse Actian Vector for Hadoop peut apporter ces améliorations dans votre environnement de big data Hadoop.
Actian Vector for Hadoop a démontré une performance de requête supérieure d'un à trois ordres de grandeur en comparaison avec d'autres alternatives majeures de SQL dans Hadoop. Dans ce premier article d'un blog en trois parties décrivant les résultats, nous montrerons les résultats de performance stupéfiants et expliquerons les facteurs qui contribuent à un tel avantage. La deuxième partie couvrira les capacités uniques de Vector à gérer les mises à jour, et la troisième partie traitera de l'efficacité du format de fichier Vector for Hadoop.
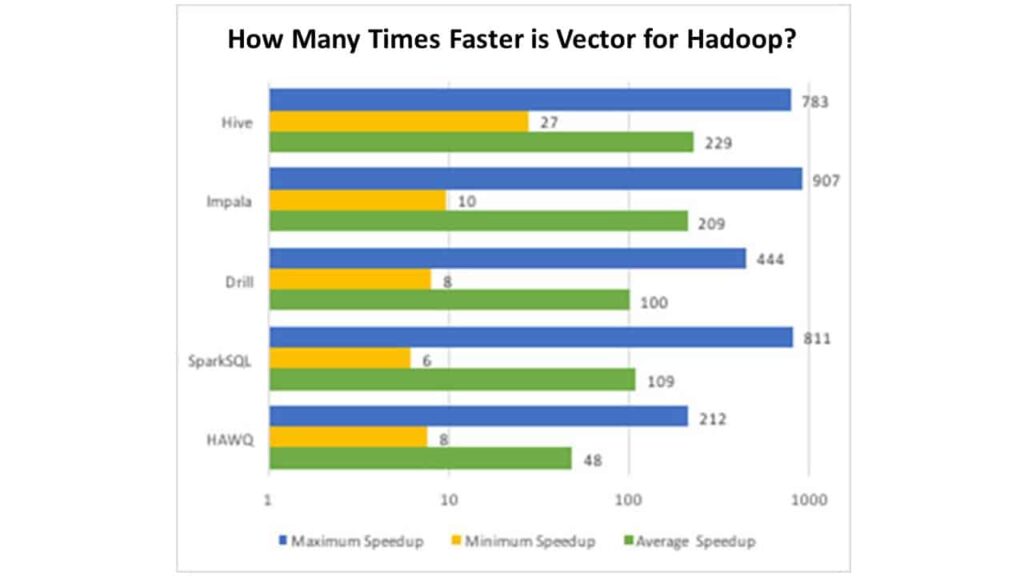
L'équipe d'ingénierie des performances d'Actian a utilisé l'ensemble des 22 requêtes TPC-H pour effectuer des tests non vérifiés sur plusieurs des solutions SQL sur Hadoop du marché, et les résultats pourraient vous surprendre (mais pas nous). En voici un bref résumé :
Ces résultats ont été publiés dans un article universitaire soumis et présenté à la Conférence internationale sur la gestion des données (ACM SIGMOD). Cet article explique en détail comment Vector pour Hadoop est capable d'atteindre un tel avantage en termes de performances - en voici la version courte :
- Exécution efficace, multi-cœur parallèle et vectorisée - Vector for Hadoop est conçu pour tirer parti des caractéristiques de performance de l'architecture Intel processeur , y compris le jeu d'instructions vectorielles AVX2 et les caches multicouches de grande taille.
- Optimiseur de requête bien réglé - Vector for Hadoop étend l'optimiseur mature de sa version SMP originale pour exploiter les multiples niveaux de parallélisme et les avantages de la localité des données dans un système MPP Hadoop. L'optimiseur Vector for Hadoop peut modifier l'ordre de jointure ou partitionner les tables de données pour améliorer les opérations parallèles, étapes qui doivent être effectuées manuellement pour les requêtes dans les autres alternatives.
- Contrôle de la localité des blocs HDFS - Vector pour Hadoop fonctionnant nativement au sein de HDFS et YARN, il peut participer à la gestion des ressources et prendre des décisions d'allocation dans le contexte de la charge de travail d'un cluster plus large. Parallèlement, des optimisations spécifiques du stockage des tables réduisent les frais généraux, accélèrent les lectures, maximisent l'efficacité des disques et réduisent l'asymétrie des données afin d'accélérer les résultats des requête .
- Filtrage efficace des E/S - le suivi de la plage de valeurs d'une colonne (MinMax) permet d'ignorer la lecture des blocs qui se situent en dehors de la plage de la requête, ce qui réduit les E/S sur disque et les délais de lecture, et évite les calculs de décompression, parfois de manière significative.
- Compression légère - La compression de Vector permet d'atteindre de bons niveaux de compactage à grande vitesse, ce qui accélère l'exécution vectorielle en minimisant les branchements et le nombre d'instructions. Nos algorithmes de compression sont capables de fonctionner entièrement dans le cache du processeur , ce qui augmente efficacement la bande passante de la mémoire. Différents algorithmes de compression sont adaptés aux divers types de données et Vector les calibre et les choisit automatiquement pour atteindre des niveaux de compression et d'efficacité supérieurs à ceux des algorithmes de compression généraux.
Comment les tests ont-ils été effectués ?
- Actian performance engineering a construit un Cluster Hadoop de 10 nœuds, chaque nœud 2xIntel 3.0GHz E5-2690v2 CPUs, 256GB RAM, 24x600GB HDD, 10Gb Ethernet, Hadoop 2.6.0. Il y avait un nœud de nom et neuf nœuds SQL-on-Hadoop, configurés à l'aide de Cloudera Express 5.5.
- Ces tests ont été réalisés au début de l'année 2016, en exécutant la version la plus récente de chacune des alternatives SQL sur Hadoop (Actian Vector for Hadoop 4.2.2, Apache Hive 1.2.1, Cloudera Impala 2.3, Apache Drill 1.5, Apache Spark SQL 1.5.2, et Pivotal HAWQ 1.3.1). Des efforts raisonnables ont été faits pour optimiser chaque plateforme afin d'établir des comparaisons équitables.
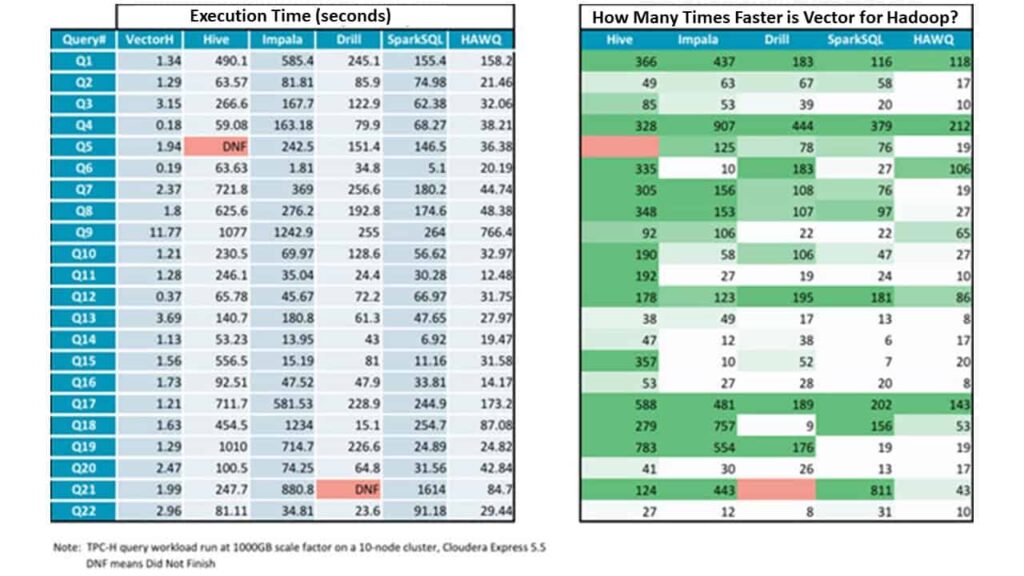
Voici les temps d'exécution des requête individuelles et le facteur d'accélération de Vector pour Hadoop par rapport à chacune des alternatives :
Dans la deuxième partie de cette série de blogs, nous aborderons les avantages de Vector for Hadoop 6.0 en termes de fonctionnalité SQL et de capacité de mise à jour des données par rapport aux autres solutions, et la troisième partie montrera les avantages du format de fichier Vector pour des performances de requête plus rapides et des besoins de stockage moindres.
S'abonner au blog d'Actian
Abonnez-vous au blogue d'Actian pour recevoir des renseignements sur les données directement à vous.
- Restez informé - Recevez les dernières informations sur l'analyse des données directement dans votre boîte de réception.
- Ne manquez jamais un article - Vous recevrez des mises à jour automatiques par courrier électronique pour vous avertir de la publication de nouveaux articles.
- Tout dépend de vous - Modifiez vos préférences de livraison en fonction de vos besoins.