
Die effektive, effiziente und wirtschaftliche Verwaltung von Daten ist für den Erfolg eines Unternehmens von entscheidender Bedeutung. Daten unterstützen Expertenmeinungen von Menschen und liefern Input für Entscheidungen von neuen Technologien wie Maschinelles Lernen, business intelligenceund Lösungen der künstlichen Intelligenz.
Die Verwaltung historischer und kumulierter Daten kann schwierig sein. Daten, die aus zahlreichen Quellen in verschiedenen Formaten und mit unterschiedlichen Benennungskonventionen gesammelt werden, stellen eine große Herausforderung für die Organisation dar. Dies erschwert es, den Daten eine einheitliche Bedeutung zu geben und den Personen und Anwendungen, die die Daten zur Entscheidungsfindung nutzen, Zugang zu verschaffen. Eine Data-Warehouse-Architektur kann bei der Bewältigung dieser komplexen Situation helfen.
Was ist eine Data-Warehouse-Architektur?
Die Data-Warehouse-Architektur besteht aus der Planung, dem Entwurf, der Konstruktion und der Verwaltung der täglichen Betriebsprozesse für die Nutzung von Daten für organisatorische Intelligenz und Entscheidungsunterstützung. Eine Data-Warehouse-Architektur hilft bei der Schaffung einer einzigen Wahrheitsquelle für große Datenmengen, die aus verschiedenen und unterschiedlichen Datenquellen stammen. Innerhalb der Data-Warehouse-Architektur werden die Daten dann in Informationen umgewandelt, und die Informationen werden in Wissen für Analysen umgewandelt.
Der Datenlebenszyklus umfasst die Datenerfassung aus bestimmten Quellen, die Verwaltung der Datenintegrität und den Datenabgleich, die Datenspeicherung, die Datenübertragung und die kontinuierliche Verbesserung der Daten im Hinblick auf die organisatorische Reife, die Analysen und die Entscheidungsanforderungen. Die Data-Warehouse-Architektur muss diese Aktivitäten und andere Aspekte des Datenlebenszyklusmanagements unterstützen.
Data-Warehouse-Architekturen sind in der Regel auf Stakeholder, z. B. für Vertrieb, Marketing und andere. Obwohl sie gemeinsame Daten verwenden, hat jeder Stakeholder andere Anforderungen an die Modellierung und Datenanalyse für seine Entscheidungen. Dazu gehören die Menschen, die verschiedene Tools verwenden, sowie die Art und Weise, wie Technologien oder Anwendungen die Daten nutzen, um sie in Informationen und Entscheidungen umzuwandeln.
Arten von Data-Warehouse-Architekturen
Es ist keine gute Praxis, die analytische Verarbeitung mit einer transaktionalen Datenbank zu unterstützen, da dies zu Leistungsproblemen führt. Transaktionsdatenbanken sind für die Verarbeitung großer Mengen von Transaktionen in Echtzeit optimiert, während analytische Datenbanken für langwierige, ressourcenintensive Abfragen optimiert sind. Aus diesem Grund sollten Transaktionsdaten eher als Input für die Data-Warehouse-Datenbank dienen, als dass sie sowohl transaktionale als auch analytische Anforderungen unterstützen.
Es gibt verschiedene Data-Warehouse-Modelle wie z.B.:
Grundlegende Data Warehouse Architektur - Single Tier
Diese Architektur minimiert die Menge der gespeicherten Daten und Datenredundanzen. Sie wird nicht häufig verwendet, kann aber die Bedürfnisse einiger kleinerer Organisationen kennenlernen , die keinen unternehmensweiten Zugriff auf Daten benötigen. Leistungsprobleme treten häufig auf, wenn Analyse- und Transaktionsverarbeitung nicht voneinander getrennt sind.
Data Warehouse-Architektur mit zentralem Lager - Two Tier
Diese Architektur verwendet Staging, um bestimmte Daten zu extrahieren, Daten für die Verwendung umzuwandeln und sie in ein Data Warehouse zu laden. Dieser Prozess wird als Extraktion, Transformation und Laden(ETL) bezeichnet. Eine der Extraktionsquellen kann eine transaktionale Datenbank sein. Die Informationen werden in einem logisch zentralisierten individuellen Lager, einem Data Warehouse, gespeichert, das mit Analysetools gekoppelt ist. Data Marts können in eine zweistufige Data-Warehouse-Architektur eingebunden werden, um gezielte Nutzer bereitzustellen.
Data Warehouse-Architektur mit einem zentralen Lager und einem OLAP-Server - dreistufig
Bei dieser Architektur wird der zweistufige Aufbau um einen OLAP-Server (On-Line Analytical Processing) ergänzt. Diese mittlere Schicht bietet eine abstrahierte Sicht auf die Datenbank für den Nutzer und trägt zur scalability und Leistung des Systems bei.
In jeder der aufgeführten Data-Warehouse-Architekturen gibt es immer Raum für zusätzliche Optimierungen, z. B. die Verwendung von Clustern zur Dezentralisierung der Datenverwaltung und -verarbeitung. Dies könnte bei Herausforderungen im Zusammenhang mit der data governance auf lokaler oder internationaler Ebene nützlich sein. Data-Warehouse-Architekturen können Bus-, Hub-and-Spoke- und föderierte Modelle umfassen, um spezifische Anforderungen zu erfüllen.
Das folgende Diagramm zeigt eine dreistufige Data-Warehouse-Architektur. Die Data-Warehouse-Struktur kann auf jeder Ebene geändert werden, um mehr ähnliche Komponenten einzubauen, wie z. B. eine Erhöhung der Anzahl der Data Marts, um zusätzliche Funktionseinheiten im Unternehmen zu unterstützen.
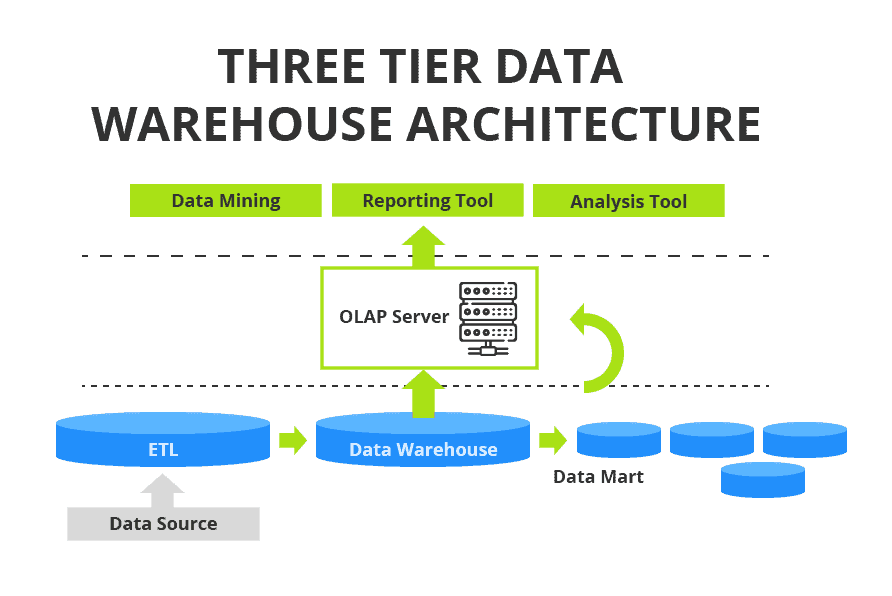
Diagramm der Data-Warehouse-Infrastruktur
Die wichtigsten Komponenten einer Data-Warehouse-Architektur sind:
- Datenquellen - Datenbanken und andere Dateien, einschließlich einer Transaktionsdatenbank.
- Das Data Warehouse selbst.
- Data Marts - für spezifische Stakeholder Funktionen.
- OLAP Server - ermöglicht eine schnelle und flexible multidimensionale Datenanalyse.
- Tools, die Stakeholder für den Zugriff auf Analysen (Anwendungen) verwendet.
Einer der Werte der Architektur im Data Warehousing ist die Einfachheit. Ein Unternehmen kann mit einer Grundstruktur beginnen, die nur wenige Komponenten enthält, und diese später in verschiedenen Teilen der Architektur ergänzen, wenn sich die Datenstrategie weiterentwickelt. Grundsätzlich sollte man die Designstruktur beibehalten und die spezifischen Elemente wie Datenquellen erweitern, um der Lösung Tiefe und Breite zu verleihen.
Eigenschaften von Data-Warehouse-Architekturen
Data-Warehouse-Architekturen sollten sich auf die analytische Verarbeitung konzentrieren. Die transaktionale Verarbeitung sollte separat in einer anderen Datenbank erfolgen. Eine Datenbank für die Transaktionsverarbeitung sollte eine Datenquelle für das umfassendere Data Warehouse sein.
Weitere Eigenschaften des Data Warehouse sollten sein:
- Die Fähigkeit, die Nutzung von Daten für Analysen schnell zu skalieren. Dies kann ein wesentlicher Faktor für die Verbreitung abgeleiteter Analysen sein, die die neuesten Daten für die spezifischen Entscheidungen, die getroffen werden müssen, berücksichtigen.
- Die Architektur sollte problemlos zusätzliche Daten unterstützen, ohne dass das gesamte System umgestaltet werden muss.
- Die Daten müssen angemessen gesichert werden. Das Data Warehouse enthält Daten über die gesamte Organisation. Eine Kompromittierung ist hier riskant und könnte sehr kostspielig sein.
- Extraktions-, Transformations- und Ladetools sollten verschiedene Datenquellen unterstützen.
- Die Verwaltung der Architektur sollte nicht übermäßig kompliziert sein und im Interesse der Benutzerfreundlichkeit und besserer analytischer Ergebnisse vereinfacht werden.
- Die Data-Warehouse-Architektur im data mining Anwendungen sollten vertrauenswürdige Daten verwenden, die ordnungsgemäß extrahiert, umgewandelt und in das Data Warehouse geladen wurden. Data mining , die nicht über gute Daten verfügen, liefern nur ungenaue Ergebnisse.
- Wenn das Unternehmen reift und versteht, wie man Daten nutzt, sollte die Data-Warehouse-Lösung in der Lage sein, sich schnell an Änderungen anzupassen.
Data-Warehouse-Architekturen sollten auch ein gewisses Maß an Garantie in Bezug auf Verfügbarkeit, Sicherheit, Kapazität und Kontinuität der Nutzung bieten. Diese Elemente der Servicegarantie für das Data Warehouse sollten auch die usability und die Leistung umfassen.
Das Data Warehouse sollte Tools und Anwendungen wie Berichterstattung, data mining und Anwendungsentwicklungstools problemlos unterstützen.
Traditionelles Data Warehouse vs. Cloud Data Warehouses
Wie bereits erwähnt, handelt es sich bei einem Data Warehouse um eine Sammlung von Daten aus verschiedenen Quellen, die zu einem umfassenderen Data Warehouse für die primäre analytische Verarbeitung zusammengeführt werden, um Entscheidungen für mehrere Interessengruppen innerhalb des Unternehmens zu unterstützen. Der Unterschied zwischen einem herkömmlichen Data Warehouse und einem Cloud Warehouse hängt mit der allgemeinen Leistungsfähigkeit des Cloud Computings zusammen.
Cloud Data Warehouses ermöglichen es dem Unternehmen:
- Profitieren Sie von unbegrenztem Speicherplatz, schneller Elastizität und scalability.
- Verbesserung der Flexibilität zur Unterstützung unterschiedlicher Architekturen.
- Verbesserung der Mobilität und des Zugangs zu Daten.
- Unterstützt Big Data besser als typische On-Premises .
- Schnellere Bereitstellung als bei On-Premises-Lösungen.
- Gewinnen Sie mehr Sicherheit bei der Wiederherstellung im Katastrophenfall.
- IT-Ressourcen effizienter nutzen.
Unternehmen können auch kreativ sein und eine hybride Lösung verwenden , die das Beste aus On-Premises und Cloud nutzt, um ihre Data Warehouse-Ergebnisse für verschiedene Interessengruppen zu unterstützen.
OLAP-Lösungen können für beide Architekturen genutzt werden. OLAP ermöglicht die multidimensionale Analyse von Data-Warehouse-Daten, Informationen und Wissen zur Unterstützung komplexer Modellierungen und Trendanalysen der Data-Warehouse-Lösung. Business Intelligence (BI) und Entscheidungsfindung in allen Funktionsbereichen des Unternehmens, die Data Warehouses nutzen, können OLAP für schnelle, effektive und reaktionsschnelle Analysen nutzen.
Der Erfolg von Data-Warehouse-Lösungen hängt davon ab, dass man die Entscheidungsanforderungen des Unternehmens versteht. Jeder Stakeholder sollte anders behandelt werden, da die Art und Weise, wie und wann sie Entscheidungen treffen, unterschiedlich ist. Wenn möglich, sollten Sie den Nutzer Self-Service ermöglichen, um Konfigurationsänderungen daran vorzunehmen, auf welche Daten und wie auf diese mit ihren Anwendungen zugegriffen wird. Die Stakeholder müssen Feedback zur ETL-Verarbeitung geben, um sicherzustellen, dass die Daten verständlich sind und ihren Anforderungen entsprechen. Die Stakeholder und der Data-Warehouse-Support müssen kooperativ und koordiniert zusammenarbeiten, um die Daten und das Data-Warehouse zu verwalten, weiterzuentwickeln und in eine effektive, effiziente und wirtschaftliche Lösung für das Unternehmen umzuwandeln.


