Wie Actian Vector Ihnen bei der Beseitigung von OLAP-Würfeln hilft
Actian Germany GmbH
April 16, 2018
OLAP-Cubesanalytische Verarbeitung online) werden heute in großem Umfang eingesetzt, da viele Datenbankplattformen große Datenmengen nicht schnell analysieren können. Das liegt daran, dass die meiste Datenbanksoftware die Rechenleistung und den Arbeitsspeicher nicht voll ausnutzt, um eine optimale Leistung zu erzielen. Einige der Symptome dafür sind:
- Große Abfragen beanspruchen die Serverressourcen.
- Die Reaktion wird langsamer, wenn die Datenmenge und die Anzahl der Benutzer zunehmen.
- Die Unterstützung gleichzeitiger Abfragen wird schwierig oder unmöglich.
- Zusätzliche aggregierte/materialisierte Tabellen, Indizes und manchmal sogar individuelle Data Marts liefern nicht die erforderliche Leistung und Zustimmung.
OLAP Cube wurden entwickelt, um die Anforderungen von Nutzerzu erfüllen, die große Datenmengen für eine Reihe vorgegebener Fragen schnell aggregieren, zerschneiden und würfeln wollen. Jetzt werden wir uns ansehen, wie wir Actian Vector, unsere spaltenbasierte Hochgeschwindigkeits-Analysedatenbank, die Verwendung von OLAP Cubes überflüssig macht.
Was sind die Nachteile der Verwendung von OLAP Cube ?
- Zusätzliche Investitionen in Hardware/Software und laufende Wartungskosten.
- Völlig neue Kenntnisse in Multi-Dimensional Expressions (MDX) sind erforderlich, um die OLAP-Würfel Anfrage .
- schreibt ein strenges Schema (Stern oder Schneeflocke) vor, während einige Cube-Speicher der neueren Generation 3NF-Tabellen (oder ROLAP-Modelle) unterstützen. Die beste Leistung wird jedoch immer mit einem Star-Schema erzielt.
- Sie schränken die Freiheit der Anfrage ein. Bei der Gestaltung des OLAP Cube muss viel bedacht werden. Sobald er erstellt ist, stehen nur die enthaltenen Zeilen und Spalten für Abfragen zur Verfügung. Oft ist für jede neue Anfrage ein neuer Cube erforderlich.
- Dies führt zu einem erheblichen Mehraufwand an Verarbeitungszeit und schafft neue Engpässe im BI-Lebenszyklus. Der Nutzer würde viel Zeit verlieren, wenn der OLAP Cube nicht korrekt erstellt wurde. Die Aktualität der Daten wird beeinträchtigt, da die Daten von den operativen Systemen über das Data Warehouse zum OLAP Cube und dann zu den BI-Tools wandern müssen.
Ein Blick unter die Haube
Schauen wir uns einmal an, was Sie mit einem OLAP Cube aufgeben. Hier ist ein einfaches Beispiel, bei dem die Rohdaten in der zugrunde liegenden relationalen Datenbank wie folgt aussehen:
| Verkauf _Datum | Jahr | Monat | Jahrzehnt | Stadt _id | Stadt _Name | Staat | Region _id | Region _Name | Produkt _id | Produkt _Name | Umsatz _Betrag |
| 1/1/1990 | 1990 | Januar | 1990-2000 | 1 | Palo alto | CA | 1 | US-West | 1 | Bolzen | 20 |
| 1/2/1990 | 1990 | Januar | 1990-2000 | 1 | Palo alto | CA | 1 | US-West | 1 | Bolzen | 23 |
| 1/3/1990 | 1990 | Januar | 1990-2000 | 1 | Palo alto | CA | 1 | US-West | 1 | Bolzen | 15 |
| 1/1/1993 | 1993 | Januar | 1990-2000 | 1 | Palo alto | CA | 1 | US-West | 2 | Hammer | 14 |
| 5/1/1993 | 1994 | Mai | 1990-2000 | 2 | La Jolla | CA | 2 | US-West | 3 | Schrauben | 60 |
| 1/1/2003 | 2003 | Januar | 2000-2010 | 3 | Dallas | TX | 1 | US-Süd | 1 | Bolzen | 12 |
| 5/1/1993 | 1993 | Mai | 2000-2010 | 4 | Atlanta | GA | 2 | US-Süd | 3 | Schrauben | 34 |
| 10/1/2004 | 2004 | Oktober | 2000-2010 | 5 | New York | NY | 1 | US-Ost | 1 | Bolzen | 35 |
| 10/2/2004 | 2004 | November | 2000-2010 | 6 | Boston | MA | 1 | US-Ost | 1 | Bolzen | 37 |
| 10/3/2004 | 2004 | Dezember | 2000-2010 | 1 | Palo Alto | CA | 1 | US-West | 1 | Bolzen | 39 |
| 10/4/2004 | 2004 | Januar | 2000-2010 | 1 | Palo Alto | CA | 1 | US-West | 1 | Bolzen | 42 |
| 10/5/2004 | 2004 | Februar | 2000-2010 | 7 | Madison | WI | 1 | US-Zentrale | 1 | Bolzen | 44 |
| 10/6/2004 | 2004 | März | 2000-2010 | 8 | Chicago | IL | 1 | US-Zentrale | 2 | Hammer | 46 |
| 4/1/2011 | 2011 | April | 2010-2020 | 9 | Salt Lake City | UT | 2 | US-West | 3 | Schrauben | 49 |
| 5/2/2012 | 2012 | Mai | 2010-2020 | 1 | Palo Alto | CA | 2 | US-West | 1 | Bolzen | 51 |
| 6/3/2013 | 2013 | Juni | 2010-2020 | 2 | La Jolla | CA | 2 | US-West | 3 | Schrauben | 53 |
| 7/4/2014 | 2014 | Juli | 2010-2020 | 10 | Jersey City | NJ | 2 | US-Ost | 1 | Bolzen | 56 |
Wenn ein Nutzer daran interessiert ist, einen einfachen OLAP Cube für die Verkäufe aus den obigen Daten zu erstellen und die interessierenden Metriken sales_amounts für jedes Jahrzehnt, Jahr, nach Produkt und Region zu aggregieren, würde der OLAP Cube die folgenden Daten enthalten:
| Dekade | Jahr | Region_Name | Produkt_name | Umsatz_Amt | Avg_Preis |
| 1990-2000 | 1994 | US-West | Schrauben | $60.00 | $19.33 |
| 1990-2000 | 1993 | US-Süd | Schrauben | $34.00 | $14.00 |
| 1990-2000 | 2003 | US-Süd | Bolzen | $12.00 | $60.00 |
| 2000-2010 | 2004 | US-Zentrale | Bolzen | $44.00 | $34.00 |
| 2000-2010 | 2004 | US-Central | Hammer | $46.00 | $12.00 |
| 2000-2010 | 2004 | US-Ost | Bolzen | $72.00 | $44.00 |
| 2000-2010 | 2004 | US-West | Bolzen | $81.00 | $46.00 |
| 2000-2010 | 2011 | US-West | Schrauben | $49.00 | $36.00 |
| 2010-2020 | 2012 | US-West | Bolzen | $51.00 | $40.50 |
| 2010-2020 | 2013 | US-West | Schrauben | $53.00 | $49.00 |
| 2010-2020 | 2014 | US-Ost | Bolzen | $56.00 | $51.00 |
| 2010-2020 | 1994 | US-West | Schrauben | $60.00 | $53.00 |
Die Daten werden nach Jahrzehnt, Jahr, Region_name, Produkt_name aggregiert. Die Details auf Transaktionsebene gehen dabei verloren. Aus diesem Grund bieten einige der ausgereifteren OLAP Cube eine Drill-Through-Funktion, die dem Nutzer einen Blick auf die detaillierten Daten ermöglicht. Die Leistung kann sich jedoch verschlechtern, wenn die Datenmenge hinter der Aggregation groß ist.
Eine typische Anfrage , um diese Daten aus dem Würfel zu erhalten, würde wie folgt aussehen, je nachdem, was der Nutzer an Zeilen und Spalten und Datenpunkten sehen möchte.
WITH
MEMBER[measures].[durchschnittlicher Preis] AS
'[measures].[sales_amt] / [measures].[sales_num]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} ON COLUMNS,
{[produkt].mitglieder, [jahr].mitglieder} ON ROWS
FROM UMSATZ_KUBUS
Der Avg_price ist eine berechnete Kennzahl. Beachten Sie, dass berechnete Kennzahlen in der OLAP Cube angegeben oder in der Anfrage definiert werden können. Einer der Vorteile von berechneten Kennzahlen, die in OLAP-Cubes definiert sind, besteht darin, dass die berechnete Kennzahl automatisch mit den neuen Parametern neu berechnet wird, wenn die Anfrage so geändert wird, dass sie einen Filter enthält oder eine zusätzliche Dimension hinzugefügt wird.
Der OLAP Cube ist also eine teilweise Lösung für das Problem, dass zeilenorientierte relationale Datenbanken für analytische Abfragen einfach nicht schnell genug sind. Was würden sich Ihre OLAP-Benutzer wünschen, wenn sie alles haben könnten, was sie wollen? Wir hören von den Anwendern diese Anforderungen:
- OLAP-ähnliche Geschwindigkeit oder besser mit vollständiger Anfrage
- Die Möglichkeit, jedes beliebige Datenmodell zu verwenden
- Alle ihre bevorzugten BI-Tools
- Die aktuellsten verfügbaren Daten
- Zugriff auf alle Detaildaten in derselben Anfrage und ohne Leistungseinbußen
Klingt unmöglich? Ist es aber nicht. Actian Vector kann all dies und noch viel mehr bieten. Wie ist das möglich? Lesen Sie weiter!
Ersetzen von OLAP-Würfeln durch Vektoren
Actian Vector ist einzigartig positioniert, um OLAP Cubes zu ersetzen. Wir haben es von Grund auf mit einer Reihe von Optimierungen entwickelt, um die Leistung von analytischen Abfragen drastisch zu steigern. Hier ist eine kurze Zusammenfassung dessen, was wir entwickelt haben:
- Vektorielle Verarbeitung: Die Vektorisierung hebt die Parallelisierung auf die nächste Stufe, indem ein single instruction an multiple data gesendet wird, die nahezu in Echtzeit reagieren.
- Vertikale Speicherung: Columnar reduziert den IO erheblich, indem nur die in einer Anfrage benötigten Spalten in den Speicher geladen werden, im Gegensatz zum Laden aller Spalten in den Speicher und dem anschließenden Auswählen der zur Erfüllung der Anfrage benötigten Spalten.
- Optimierter In-Memory: Erweiterte Nutzung von Prozessor-Cache und Hauptspeicher sowie in-memory und -Dekompression beschleunigen den Prozess.
- Flexibel: Vector arbeitet mit jedem Datenmodell - Stern, Schneeflocke, 3NF und de-normalisiert - und eliminiert die Notwendigkeit, jede Art von Materialisierung von Daten zu erstellen. Da der Nutzer von der Datenquelle ausgeht, geht die Freiheit der Anfrage nicht verloren.
- Funktionsvielfalt: Erweiterte OLAP/Windows-Funktionen ermöglichen es dem Nutzer , eine Vielzahl anspruchsvoller Fragen zu stellen.
Von Würfeln zu Actian Vector wechseln
Um BI-Berichte aus OLAP-Cubes zu migrieren, ist es wichtig, die Funktionen des Cubes zu kennen, die migriert werden müssen. Dazu gehören:
- OLAP Cube - Verstehen Sie das Datenmodell des Würfels selbst und bilden Sie es auf das RDBMS zurück.
- MDX-Abfragen, berechnete Kennzahlen und Filter, die verwendet werden.
- KPIs - Wichtige Leistungsindikatoren.
- Was-wäre-wenn-Analyse für verschiedene Szenarien.
OLAP Cube
Untersuchen Sie den OLAP Cube und stellen Sie fest, auf welcher Art von Datenmodell er basiert: ROLAP, HOLAP oder MOLAP. ROLAP-Modelle beruhen auf Datenmodellen der dritten Normalform (3NF), bei denen die Daten stark normalisiert sind. Bei der Verwendung von ROLAP-Modellen in Cubes kommt es in der Regel zu Leistungseinbußen.
HOLAP ist ein hybrides Modell, bei dem eine Kombination aus Stern- oder Schneeflockenmodellen, de-normalisiert und 3NF verwendet wird. Dies hat ebenfalls Leistungseinbußen zur Folge.
MOLAP ist das am meisten gewünschte zugrunde liegende Modell, bei dem ein Stern- oder Schneeflocken-Datenmodell verwendet wird und die beste Leistung liefert. Normalerweise liegen die Quelldaten in einem BI-Lebenszyklus in 3NF vor und müssen einen langen Transformationsprozess durchlaufen, um in ein Star-Schema konvertiert zu werden. Die Strafe wird im Voraus bezahlt, um später eine bessere Leistung zu erhalten.
Die folgenden Faktoren sind zu prüfen, wenn eine Anfrage an die Datenquelle verwendet wird:
- Abmessungen: Wie wird dies im Würfel erreicht. Speziell für ROLAP und HOLAP Modelle.
- Maße: Sowohl berechnete als auch normale Maße.
- Fakten: Handelt es sich um eine einzige Tabelle oder um eine Kombination von Tabellen?
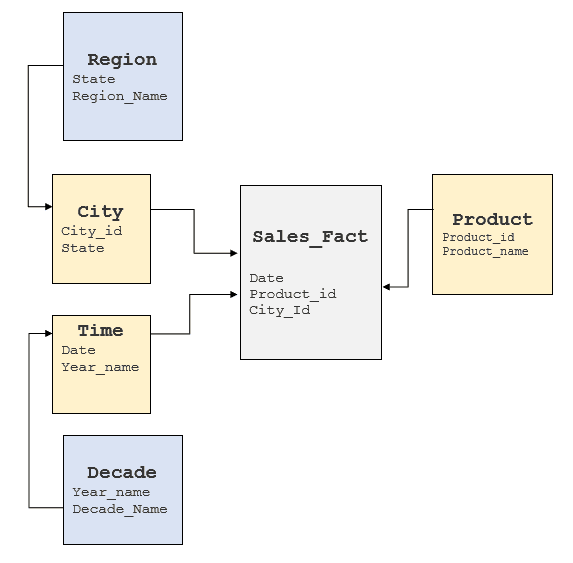
Es ist wichtig, die oben genannten Faktoren zu untersuchen, um ein Verständnis des zugrunde liegenden RDBMS zu erlangen und zu sehen, wo diese Elemente zu finden sind. In der Regel sind in Data Warehouses Stern- oder Schneeflockenmodelle implementiert, aber einige Data Warehouses neigen dazu, ein stark normalisiertes Modell zu haben. Für den obigen Cube würde ein typisches Schneeflockenmodell wie folgt aussehen:
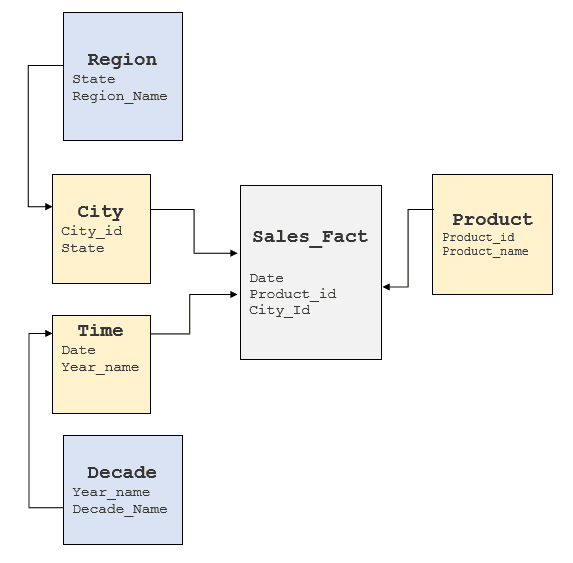
MDX-Abfragen in SQL umwandeln
Untersuchen Sie die Anfrage und identifizieren Sie die folgenden Elemente des OLAP Cube und der Anfrage. Ziehen Sie bei Bedarf ein grundlegendes MDX-Lernprogramm zu Rate. Das müssen Sie wissen:
- Abmessungen
- Maßnahmen
- Berechnete Maßnahmen
- Datenausschnitte oder Filter (Beispiel: Wenn der Nutzer nur die Verkäufe für "Bolzen" oder nur für den Monat Januar wissen möchte).
Nehmen wir die Anfrage aus dem vorherigen Abschnitt als Beispiel:
WITH
MEMBER[measures].[durchschnittlicher Preis] AS
'[measures].[sales_amt] / [measures].[sales_num]'
SELECT
{[measures].[sales_sum],[measures].[avg price]} ON COLUMNS,
{[produkt].mitglieder, [jahr].mitglieder} ON ROWS
FROM UMSATZ_KUBUS
Wo:
- Der Durchschnittspreis ist ein berechnetes Maß
- Sales_amt ist eine Kennzahl, die im Würfel definiert ist
- [Produkt].members ist die Produktdimension
- [Jahr].members ist das Jahr Dimension
Nun möchten Sie die MDX-Abfragen in SQL-Abfragen umwandeln, die auf dem obigen Modell basieren. Die Anfrage kann wie folgt in SQL umgeschrieben werden:
Select jahr_name, produkt_name, sum(umsatz_amt) as umsatz, avg(umsatz_amt) as avg_umsatz from Umsatz FT join Time_Dimension TD on FT.date = TD.date join Month_Dimension MD on month(TD.date) = MD.month join Year_Dimension YD on year(date) = YD.year join Stadt_Dimension RD on FT.stadt_id = RD.stadt_id join State_Dimension SD on FT.state_id= RD.state_id join Produkt PD on FT.produkt_id = PD.produkt_id group by jahr_name, produkt_name
oder die Anfrage noch weiter vereinfachen, indem die Dimensionstabellen entfernt werden, wenn sie nur zum Aufbau des Würfels eingeführt wurden:
Wählen Sie datum_teil(jahr, verkauf_datum) as jahr_name, produkt_name, sum(umsatz_amt) as umsatz , avg(umsatz_amt). as avg_umsatz from Verkauf FT join Produkt PD on FT.Produkt_id = PD.Produkt_id group by jahrzehnt,jahr_name, region_name, produkt_name
Hinweis: Es wird nicht impliziert, dass Verknüpfungen mit anderen Tabellen vollständig eliminiert werden können. Nur Tabellen, die nur eingeführt wurden, um das strenge Stern-/Schneeflockenschema einzuhalten, können eliminiert werden.
Wenn das BI-Werkzeug keine analytischen Fensterfunktionen bereitstellt, beziehen Sie sich auf die analytischen Funktionen und Fensterfunktionen von Vector, damit sie in der Datenbank ausgeführt werden können.
Wenn der Nutzer eine bestimmte Reihe von Zeilen aufschlüsseln möchte, kann die Aggregation entfernt und die Anfrage datenbankintern ausgeführt werden. Wenn der Nutzer beispielsweise an den Verkaufszahlen für das Produkt Bolzen im Januar 1993 interessiert ist, könnte er die folgende Anfrage verwenden:
Wählen Sie Datum_teil(Jahr, Verkaufsdatum) as Jahr_name, produkt_name, umsatz_amt as umsatz from Verkauf FT join Produkt PD on FT.product_id = PD.Product_id wo Produkt_name = "Schrauben" und Datum_teil(Jahr, Verkaufsdatum) = "1993" und Datum_teil(Monat, Verkaufsdatum) = "Januar"
Wichtige Leistungsindikatoren
In der Wirtschaftsterminologie ist ein Leistungsindikator (Key Performance Indicator, KPI) ein quantifizierbares Maß für die Messung des Geschäftserfolgs.
Ein einfaches KPI-Objekt besteht aus: Basisinformationen, dem Ziel, dem tatsächlich erreichten Wert, einem Statuswert, einem Trendwert und einem Ordner, in dem das KPI angezeigt wird. Zu den Basisinformationen gehören der Name und die Beschreibung des KPIs. In einem Microsoft SQL Server Analysis Services-Würfel ist das Ziel ein MDX-Ausdruck, der zu einer Zahl ausgewertet wird. Der Ist-Wert ist ein MDX-Ausdruck, der als Zahl ausgewertet wird. Der Status und der Trendwert sind MDX-Ausdrücke, die als Zahl ausgewertet werden. Der Ordner ist ein vorgeschlagener Speicherort für den KPI, der dem Client angezeigt werden soll.
Einige OLAP cube bieten zwar elegante und einfach zu bedienende Schnittstellen für die Speicherung und Implementierung von KPIs und Aktionen, doch können diese leicht durch eine Kombination aus herkömmlichen Datenbankfunktionen und Anwendungscode implementiert werden.
Was-wäre-wenn-Analyse für verschiedene Szenarien
What-if-Analyse Funktionen werden von einigen Cube-Speichern mit einfach zu bedienenden Schnittstellen zur Verfügung gestellt. Diese können auch mit Datenbankfunktionen und Anwendungscode mit einigem Aufwand implementiert werden.
Diese Art der Analyse erfordert die Speicherung verschiedener Szenarien und die Analyse der Auswirkungen des aktuellen Geschäftsverlaufs im Vergleich zu diesen verschiedenen Szenarien. Dies wird üblicherweise in Finanzdienstleistungs-/Handelsunternehmen eingesetzt, um das Risiko und die Auswirkungen des Handels ständig zu bewerten.
Eine detaillierte Analyse der Anforderungen wäre erforderlich und würde den Rahmen dieses Blogbeitrags sprengen.
Zusammenfassung
Für OLAP-Anwender, die den BI-Lebenszyklus vereinfachen wollen, bietet die Actian Vector Analytics Datenbank mit ihrer bahnbrechenden Technologie, überlegenen Performance und datenbankinternen analytischen Funktionen eine praktikable Alternative zu OLAP Cubes. Der Nutzen der Migration liegt in reduzierten Kosten und einer besseren Nutzer durch Anfrage .
Glauben Sie nicht nur an mein Wort. Probieren Sie es selbst aus. Wir haben eine Anleitung und eine Testversion von Vector vorbereitet, zusammen mit allen Materialien, die Sie benötigen, um Vector in etwa einer Stunde zu testen. Hier können Sie unserer aktiven Vector-Community Fragen stellen.
Abonnieren Sie den Actian Blog
Abonnieren Sie den Blog von Actian, um direkt Dateneinblicke zu erhalten.
- Bleiben Sie auf dem Laufenden - Holen Sie sich die neuesten Informationen zu Data Analytics direkt in Ihren Posteingang.
- Verpassen Sie keinen Beitrag: Sie erhalten automatische E-Mail-Updates, die Sie informieren, wenn neue Beiträge veröffentlicht werden.
- Ganz wie sie wollen: Ändern Sie Ihre Lieferpräferenzen nach Ihren Bedürfnissen.