High-Performance Echtzeitanalysen auf Hadoop-Daten
Maria Schulte
Dezember 27, 2017

Die Herausforderung
Ich habe viele Jahre mit Actians Kunden an Datenbanklösungen gearbeitet und dachte, es wäre nützlich, eine kürzlich Customer-Experience bei einem großen Medienunternehmen (ich werde es "XYZCo" nennen) zu diskutieren. Diese Erfahrung ähnelt dem, was ich immer wieder bei anderen Kunden erlebe, und die daraus gezogenen Lehren gelten sowohl für Hadoop- als auch für Nicht-Hadoop-Anwendungsfälle.
In diesem Fall kam das Big Data von XYZCo zu Actian, weil esEchtzeitanalysen für seine Hadoop-Daten benötigte und seine aktuellen Systeme nicht in der Lage waren, die Geschäftserwartungen zu kennenlernen . Sie standen unter enormem Druck, die Produktivität ihrer Datenanalysten zu steigern, da die Analysen einiger großer Datensätze nie abgeschlossen werden konnten. Außerdem mussten sie den Overhead und die Verzögerungen bei der Datenverarbeitung reduzieren, um Data Warehouse-Analysen und Berichte in Echtzeit zu ermöglichen.
Die Situation
Der Kunde hatte zwei sehr große Fakten- und Dimensionstabellen in seiner Datenbank. Um geschäftliche Fragen zu Kundenabwanderung, Lebenszeitwert und Markt zu beantworten, mussten die beiden Tabellen miteinander verbunden werden, um Abfragen durchzuführen.
Da Legacy-Datenbanken und Hadoop-Lösungen beim Zusammenführen von Daten so ineffizient sind (manchmal werden große Joins nie abgeschlossen), hatte XYZCo die Praxis übernommen, die Tabellen zusammenzuführen und eine zwischengeschaltetePre-Join/Materialisierungstabelle zu erstellen, gegen die nachfolgende Abfragen ausgeführt wurden. Diese Methode funktionierte, hatte aber mehrere Probleme: Die Pre-Join-Tabelle, die Materialisierung, war RIESIG; sie war exponentiell so groß wie Tabelle1 und Tabelle2 (und nicht nur Kopien von Tabelle1 und Tabelle2), und unmittelbar nach der Erstellung war die Materialisierung "veraltet"; sie konnte nicht ständig aus den sich ständig ändernden Tabellen1 und Tabelle2 aktualisiert werden, sondern blieb bei den alten Werten zum Zeitpunkt der Erstellung. Darüber hinaus war die Anfrage für diese Materialisierung nicht besonders gut, und es gab einige Abfragen, die einfach nicht funktionieren wollten... die Daten waren einfach zu groß.
Außerdem verfügte dieser Kunde über große Mengen strukturierter Daten in einem Hadoop-Datenspeicher. Er verwendete derzeit Hive zusammen mit SQL-basierten Analysetools, darunter Tableau. Der Kunde war es gewohnt, Daten über mehrere Quelltabellen hinweg zu verbinden, mit dem "gefühlten" Nutzen einer einfacheren/schnelleren Abfrage durch andere nachgeschaltete Tools und Prozesse. Außerdem wurden die meisten dieser Aggregate/Joins in CSV exportiert, um sie in andere Tools einzugeben, oder sie wurden für "vermeintlich" einfacheres SQL materialisiert, da das Schema zu einer einzigen, flachen Quelltabelle wurde.
Lösungen im Vergleich
Materialisierungstest der alten Schule
XYZCo bat uns, den Materialisierungstest im alten Stil auch mit Actian VectorH durchzuführen, der spaltenbasierten High-Performance von Actian, die nativ in Hadoop läuft, um einen direkten Vergleich mit Hive zu ermöglichen. Das haben wir getan.
Ein großer Teil der Materialisierung ist die Zeit, die für die E/A benötigt wird, um die große, materialisierte Ergebnismenge zu schreiben. Obwohl VectorH bei der Verknüpfung selbst viel schneller war als Hive, stellte der E/A-Teil des gesamten Materialisierungsprozesses jede Verknüpfungskomponente in den Schatten - ob schnell oder langsam. Obwohl VectorH bei der Verknüpfung selbst viel schneller war, führte VectorH in diesem Fall den gesamten Materialisierungsprozess in etwa demselben Zeitrahmen durch wie Hive, da ein Großteil der Zeit auf das Schreiben der Ergebnismenge entfiel, die bei beiden Produkten gleich groß war.
Nachdem wir die Abfragen mit der Materialisierung durchgeführt hatten, war VectorH etwa doppelt so schnell wie das andere Produkt. Denken Sie bei der späteren Lektüre daran, dass die Materialisierung exponentiell zur Größe der Quelltabellen ist.
Obwohl diese Ergebnisse beeindruckend sind, verblassen sie im Vergleich zu dem, was ich Ihnen im Folgenden über den On-Demand-Ansatz von Actian erzählen werde.
Echtzeitanalysen mit Actian VectorH On-Demand
Nachdem wir den obigen Test mit der Zwischenmaterialisierung nach alter Schule durchgeführt hatten, wollten wir dem Kunden einen besseren Weg zeigen. Wir haben gezeigt, dass mit VectorH Abfragen gegen die Basisdaten (ohne Zwischenmaterialisierungsschritt) mit der Verknüpfung auf Abruf um Größenordnungen schneller waren!

Hier sind die Rohdaten, die auf den Hive- und VectorH-Systemen der Kunden für die Ergebnisse eines einzelnen Laufs erfasst wurden. Beachten Sie, dass die VectorH-Tests auf einem Cluster durchgeführt wurden, der nur halb so groß war wie der Cluster. VectorH weist ausgezeichnete scalability Skalierbarkeitseigenschaften auf, daher haben wir die Ergebnisse auf eine gleichwertige Plattform normiert.
Wie bereits erwähnt, lag eine Materialisierung in der gleichen Größenordnung, VectorH war bei Abfragen gegen eine Materialisierung doppelt so schnell. Interessanter sind jedoch die Fälle, in denen Hive keine On-Demand-Join-Szenarien abschließen konnte und Actian VectorH eine enorme Geschwindigkeit zeigte.

Die oben genannten Vorteile gelten für einzelne Läufe. Was passiert in realen Situationen mit Hunderten von Kundenanfragen und laufender Datenaktualisierung?
Die folgende Tabelle zeigt, was bei 100 und 200 Kundenanfragen und einer Aktualisierung der Kundendaten passiert. Beachten Sie, dass bei der Geschwindigkeit von VectorH die alte Lösung, selbst bei Verwendung von Pre-Materialisierungen, immer langsamer ist, Zeit für die Re-Materialisierung benötigt und einfach nie aufholen kann. Der Actian VectorH-Ansatz übertrifft die Leistung der Mitbewerber. Dies gilt zusätzlich zu den anderen Vorteilen, die sich daraus ergeben, dass die Ergebnisse auf aktuellen und nicht auf veralteten Daten beruhen, dass Speicherplatz eingespart wird, dass weniger Verwaltungsaufwand anfällt und so weiter.
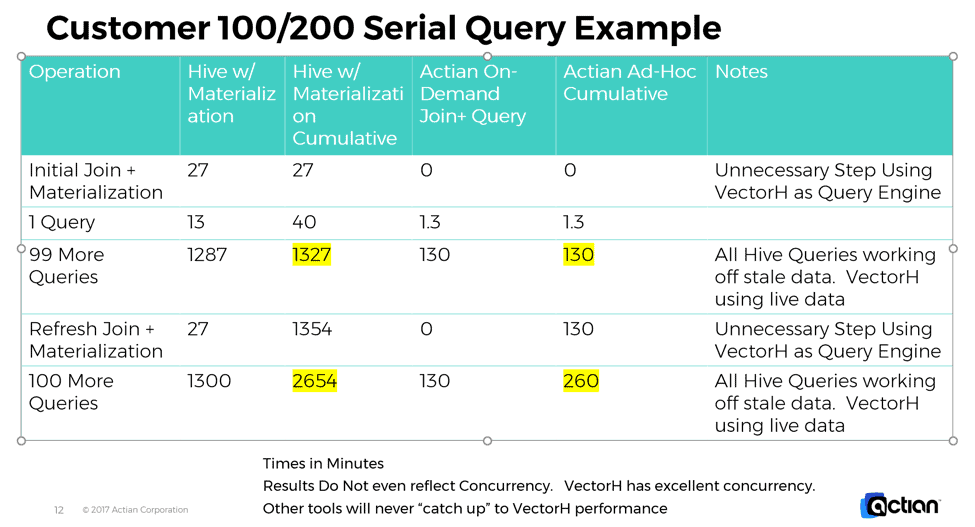
Bitte beachten Sie auch, dass diese Ergebnisse nicht einmal die Zustimmung berücksichtigen. VectorH hat unglaubliche Zustimmung. Die oben genannten Zahlen wären sogar noch besser für VectorH, wenn wir solche Zahlen in einer gleichzeitigen Situation erfasst hätten.
Schlussfolgerung
In der On-Demand-Lösung spiegelten die Anfrage IMMER die aktuellen Daten wider und nicht die Ergebnisse aus einer veralteten Materialisierung, was Echtzeitanalysen und genauere Ergebnisse.
Die Analysten mussten nicht mehr darauf warten, dass ein Snapshot erstellt wurde, und konnten ihre Verknüpfungen ad hoc vornehmen.
Die Nettoleistung war deutlich schneller als bei einer riesigen Voraggregation, da jede Anfrage nur die benötigten Daten scannt und nicht jede Zeile in einer riesigen Materialisierung, was zu weniger teurem I/O und keiner Downtime für den Wiederaufbau der Zwischenmaterialisierung führt.
Ansichten wurden verwendet, um die Verknüpfungslogik für die Endbenutzer zu verbergen und so die Abfragen zu vereinfachen. Da es keine Duplizierung von Daten durch Materialisierung gibt, wird der Speicherplatz auf ein Minimum reduziert.
Ohne eine schnelle JOIN-Engine wie VectorH ist dieser Ansatz für sehr große Datensätze in der Regel nicht praktikabel.
Nächste Schritte
Sie möchten mehr über Actian VectorH erfahren ?
Sie können Actian Vector auch herunterladen und selbst ausprobieren. Sie werden nicht enttäuscht sein, und wenn Sie Hilfe brauchen, fragen Sie einfach die Community oder wenden Sie sich an eval@actian.com, um eine 30-tägige Testversion von VectorH mit kostenlosem Enterprise Support anzufordern.

Abonnieren Sie den Actian Blog
Abonnieren Sie den Blog von Actian, um direkt Dateneinblicke zu erhalten.
- Bleiben Sie auf dem Laufenden - Holen Sie sich die neuesten Informationen zu Data Analytics direkt in Ihren Posteingang.
- Verpassen Sie keinen Beitrag: Sie erhalten automatische E-Mail-Updates, die Sie informieren, wenn neue Beiträge veröffentlicht werden.
- Ganz wie sie wollen: Ändern Sie Ihre Lieferpräferenzen nach Ihren Bedürfnissen.