Analysieren und Handeln auf Transaktionsdaten mit einem Operational Data Warehouse
Actian Germany GmbH
September 13, 2018
Wir hören immer wieder, dass zukunftsorientierte Unternehmen, ob klein oder groß, sich stärker am Kunden orientieren, ja sogar kundenbesessen sein müssen, um in dieser wettbewerbsintensiven Welt erfolgreich zu sein. Daten liefern Erkenntnisse über die Bedürfnisse und das Verhalten Ihrer Kunden, so dass Sie Ihre Botschaften und Angebote aktiv darauf abstimmen können, um sich von der Konkurrenz abzuheben und deren Kunden zu gewinnen. Dieses Wissen stammt aus einer zunehmenden Vielfalt von Quellen, die rund um die Uhr zur Verfügung stehen, aus digitalen Systemen und zunehmend aus einem Meer von Sensoren, Geräten und mobilen Anwendungen, die diese Aktivitäten aufzeichnen. Die Datenmenge kann jedoch überwältigend sein, und der Wert Ihrer Daten kann mit der Zeit schnell abnehmen. Daher ist es unerlässlich, eine Infrastruktur einzurichten, um diese verderblichen Informationen schnell zu nutzen und zu beeinflussen, wann und wie Sie mit Ihren Zielkunden in Kontakt treten. Dies erfordert einen neuen Ansatz für die Verwaltung von Daten im Moment, den wir als Operational Data Warehouse (ODW) bezeichnen. Ein ODW kann über die Berichterstattung auf der Grundlage historischer, statischer Daten hinausgehen und stattdessen mit frischen, aktiven Daten arbeiten, um spezifische Geschäftsaktionen voranzutreiben - und zwar im Moment des Geschäfts.
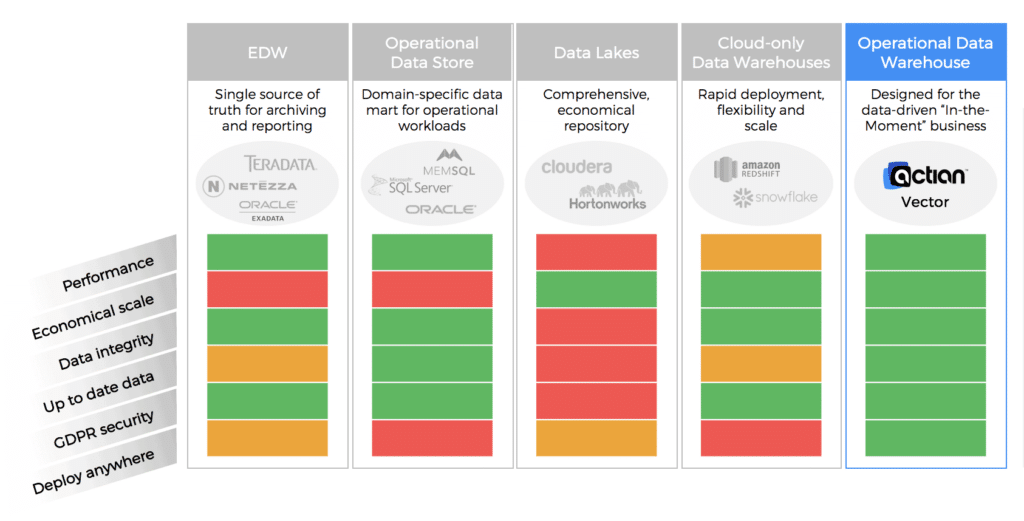
Unternehmen verfügen bereits über eine Reihe von Lösungen, um analytische Erkenntnisse zu gewinnen, von etablierten relationalen Datenbanksystemen über Enterprise Data Warehouses bis hin zu Data Lakes, in ihren Rechenzentren oder zunehmend in der Cloud. Bestehende Lösungen sind in der Regel mit einigen erheblichen Kompromissen verbunden, die ein operatives Data Warehouse überwinden kann.
Nehmen wir das traditionelle Unternehmens-Data-Warehouse, das es schon seit Jahrzehnten gibt. Es ist eine bewährte Methode zur Verwaltung historischer Daten, zur Bereitstellung von Batch-Updates, zur Unterstützung regelmäßiger Berichtszyklen und als einzige Quelle der Wahrheit für das Unternehmen. Allerdings handelt es sich dabei in der Regel um eine teure Lösung, vor allem wenn Sie die Hardware aufrüsten, die Kapazität erweitern, neue Datentypen hinzufügen und den Zugriff modernisieren müssen. Bei einem EDW, das von der IT-Abteilung sorgfältig verwaltet wird, um die Governance und die Kosten zu kontrollieren, müssen neue Berichte einen formellen Änderungsprozess durchlaufen, der die Entwicklung verlangsamen kann. Während ein EDW geplante Arbeitslasten gut bewältigt, eignet es sich schlecht für Ad-hoc-Abfragen, was es schwierig macht, Daten-Discovery zu betreiben und aussagekräftige Analysen zu erstellen, ohne bestehende Berichtslasten zu beeinträchtigen.
Eine weitere Option ist ein operativer Datenspeicher, der mehr Datenflexibilität und eine separate Umgebung für Ad-hoc-Analysen bietet, sich aber in der Regel starr auf einen Bereich oder Datentyp konzentriert und nicht umfassend ist. Wie ein EDW ist er möglicherweise nicht für die interaktive analytische Anfrage optimiert, die für die Ermittlung erforderlich ist.
Data Lakes werden von vielen als eine wirtschaftlichere und skalierbar Lösung angesehen, die Speicherplatz für viele Datenquellen und Datentypen bietet. Allerdings können sie zu einer Müllhalde für Daten mit schlechter Governance und Validierung werden. Das architektonische Erbe, das auf einen einfachen, flexiblen Dateneingang ausgelegt ist, führt wiederum zu einer langsamen Anfrage , unterdurchschnittlicher Nutzer Zustimmung und unvorhersehbaren Resultaten.
Das letzte glänzende Objekt, das auftaucht, ist die Cloud, die wirtschaftliche Speicherung und Leistung sowie unbegrenzte elastische Deployment verspricht. In der Realität können diese Cloud zu teuren oder unvorhersehbaren Rechenkosten, begrenzten Deployment mit einem hohen Potenzial für Anbieter-/Architektur-/Datenbindung und relativ neuen und unausgereiften Management- und Tools führen. Gibt es einen besseren Weg?
Die ideale Lösung für die Betriebsanalytik würde die besten Eigenschaften der oben genannten Alternativen aufweisen, ohne deren Nachteile zu haben. Dieser neue Ansatz müsste sein:
- Schnell - Die zugrunde liegende Architektur ist für die Leistung von analytischen Anfrage optimiert und erfordert nur wenig oder gar kein Tuning für bestimmte Arbeitslasten (wie Indizierung oder Aggregierung), wodurch die Vielfalt der Arbeitslasten maximiert wird.
- skalierbar - Sie würde auf große Datenkapazitäten mit wirtschaftlicher und flexibler Speicherebene skalieren und sich mit einer Vielzahl von bestehenden und neuen Datenquellen verbinden.
- Flexibel - Es würde flexible Deployment bieten, On-Premises oder auf verschiedenen Cloud .
- Aktualität - Es sollte in der Lage sein, Aktualisierungen von operativen Systemen nahezu in Echtzeit vorzunehmen, um mit dem Geschäft Schritt zu halten, ohne die Leistung laufender analytischer Abfragen zu verlangsamen.
- Robust - Es bietet Sicherheit, Zuverlässigkeit und Verwaltbarkeit auf Unternehmensebene.
- Sicher - Es würde eine Reihe von Datenschutzmechanismen bieten, um kennenlernen Sicherheitsanforderungen von Unternehmen kennenlernen und die strengeren gesetzlichen Auflagen zu erfüllen.
Diese Merkmale definieren das, was wir ein operatives Data Warehouse nennen. Mit einer solchen Lösung hätten Sie ein Datenbanksystem, das einer Vielzahl von Benutzern - von Datenwissenschaftlern bis hin zu Unternehmensanalysten - Real-Time-Insights in Echtzeit Einblicke in das Unternehmen gewährt. Es würdeDaten-Discovery und -Analysen unter Verwendung der aktuellsten operativen Daten unterstützen, ohne transaktionale Systeme und Workloads zu belasten.
Actian Vector Analytics Database wurde von Grund auf als operatives Data Warehouse entwickelt, um Daten sofort nutzen zu können. Sie ist nicht nur schnell, skalierbar und flexibel, sondern auch bereit für die Produktion mit ausgereifter Sicherheit, Verwaltung und Ressourcenmanagement.
Vector ist die schnellste Analytics Database, die auf Industriestandard-Servern, On-Premises oder in der Cloud, verfügbar ist. Das ursprüngliche Ziel war es, SQL-Code so schnell auszuführen, als wäre er in optimiertem C-Code geschrieben, indem die Vorteile der vektorisierten Befehle in Standard-CPUs sowie eines spaltenförmigen Datenformats genutzt werden, um analytische Abfragen effizienter zu verarbeiten. Dieses Ziel hat Vector erreicht und in den letzten sechs Jahren eine Reihe von beeindruckenden Benchmark-Ergebnissen Aufzeichnung erzielt. Darüber hinaus benötigt Vector keine speziellen Leistungseinstellungen oder Optimierungen wie Indizierung und Tuning, sondern bietet von Haus aus eine hervorragende Leistung. Dadurch eignet sich Vector hervorragend fürDaten-Discovery mit interaktiver Leistung und reduzierten Zykluszeiten für schnellere Iterationen, und zwar auf vollständigen Datensätzen, nicht auf Stichproben.
Vector bietet scalability von einem einzelnen Server bis hin zu Clustern mit Hunderten von Knoten, wobei das verteilte Dateisystem von Hadoop und YARN verwendet wird, um die Ressourcen verwalten und die Workload dorthin zu verteilen, wo die Daten gespeichert sind. Vector verarbeitet GBs, TBs und PBs an Daten und skaliert auf eine Anzahl von gleichzeitigen Nutzern, die weit über die anderer MPP-Lösungen hinausgeht.
Vector hat die administrative Infrastruktur von Actians etablierteren transaktionalen RDBMS übernommen und nutzt die bewährte Reife von Anfrage , Anfrage , Dateneingang, Datenqualität, Sicherheit, Zuverlässigkeit und Verwaltbarkeit. Actian DataFlow ergänzt Vector perfekt, indem es eine schnellere und intuitivere Kontrolle über Dateneingang und analytische Workflows bietet, einschließlich einer grafischen Nutzer auf Basis von KNIME, die das Erstellen und Optimieren von Anfrage erleichtert.
Die meisten Analyselösungen erwarten jedoch Batch-Updates und einmalige Schreib- und Lesezugriffe, die häufige Änderungen nicht unterstützen können. Vector verwendet eine patentierte Technik namens Positions-Delta-Bäume, um Aktualisierungen bestehender Daten zu verarbeiten, ohne die Anfrage zu beeinträchtigen. Das Ergebnis sind Analysen, die regelmäßige und häufige Aktualisierungen einbeziehen können, um die aktuellsten Einblicke in Ihr Unternehmen zu liefern.
Mit der Einführung der GDPR haben wir einen verstärkten Fokus auf Datenschutz und Sicherheit gesehen. Die Vector Versionen enthalten alle Funktionen , die für eine GDPR-konforme Deployment erforderlich sind, und die jüngsten Ergänzungen erleichtern die Verwaltung und Entwicklung sicherer Lösungen. Zum Beispiel stellt die Datenmaskierung sicher, dass nur autorisierte Benutzer die zugrunde liegenden Daten sehen können, während andere nur einen maskierten Wert sehen können.
Vector bietet eine breite Palette von Deployment , die auf Industriestandard-Servern unter Linux oder Windows laufen und auch verschiedene Hadoop-Distributionen zur Skalierung auf Clustern oder Cloud unterstützen. Vector unterstützt auch eine breite Palette von Speicheroptionen, so dass Ihr operatives Data Warehouse nicht an eine bestimmte Technologie gebunden ist.
Testen Sie Vector noch heute auf dem AWS Marketplace und erfahren Sie, was ein operatives Data Warehouse von Actian für Sie tun kann!
Abonnieren Sie den Actian Blog
Abonnieren Sie den Blog von Actian, um direkt Dateneinblicke zu erhalten.
- Bleiben Sie auf dem Laufenden - Holen Sie sich die neuesten Informationen zu Data Analytics direkt in Ihren Posteingang.
- Verpassen Sie keinen Beitrag: Sie erhalten automatische E-Mail-Updates, die Sie informieren, wenn neue Beiträge veröffentlicht werden.
- Ganz wie sie wollen: Ändern Sie Ihre Lieferpräferenzen nach Ihren Bedürfnissen.