Accelerating Spark With Actian Vector in Hadoop
Actian Corporation
May 9, 2016

One of the hottest projects in the Apache Hadoop community is Spark, and we at Actian are pleased to announce a Spark-Vector connector for the Actian Vector in Hadoop platform (VectorH) that links the two together. VectorH provides the fastest and most complete SQL in Hadoop solution, and connecting to Spark opens up interfaces to new data formats and functionality like streaming and machine learning.
Why Use VectorH With Spark?
VectorH is a high-performance, ACID-compliant analytical SQL database management system that leverages the Hadoop Distributed File System (HDFS) or MapR-FS for storage and Hadoop YARN for resource management. If you want to write in SQL and do complex SQL tasks, you need VectorH. SparkSQL is just a subset of SQL and must be invoked from a program written in Scala, R, Python, or Java.
VectorH is a mature, enterprise-grade RDBMS, with an advanced query optimizer, support for incremental updates, and certification with the most popular BI tools. It also includes advanced security features and workload management. The columnar data format in VectorH and optimized compression means faster query performance and more efficient storage utilization than other common Hadoop formats.
Why Use Spark With VectorH?
Spark offers a distributed computational engine that extends functionality to new services like structured processing, streaming, machine learning, and graph analysis. Spark as a platform for the data scientist enables anyone who wants to work with Scala, R, Python, or Java.
This Spark-Vector connector dramatically expands VectorH access to the broader reach of Spark connectivity and functionality. One very powerful use case is the ability to transfer data from Spark into VectorH in a highly parallel fashion. This ETL capability is one the most common use cases for Apache Spark.
If you are not a Spark programmer yet, the connector provides a simple command line loader that leverages Spark internally and allows you to load CSV, Parquet and ORC files without having to write a single line of Spark code. Spark is a standard supported component with all major Hadoop distributions so you should be able to use the connector by following the information on the connector site.
How Does it Work?
The connector loads data from Spark into Vector as well as retrieves data via SQL from VectorH. The first part is done in parallel: data coming from every input RDD partition is serialized using Vector’s binary protocol and transferred through socket connections to Vector end points using Vector’s DataStream API. Most of the time this connector will assign only local RDD partitions within each Vector end point to preserve data locality and avoid any delays incurred by network communications. In the case of data retrieval from Vector into Spark, data gets exported from Vector and ingested into Spark using a JDBC connection to the leader Vector node. The connector works with both Vector SMP and VectorH MPP, and with Spark 1.5.x. An overview of the data movement is shown below:
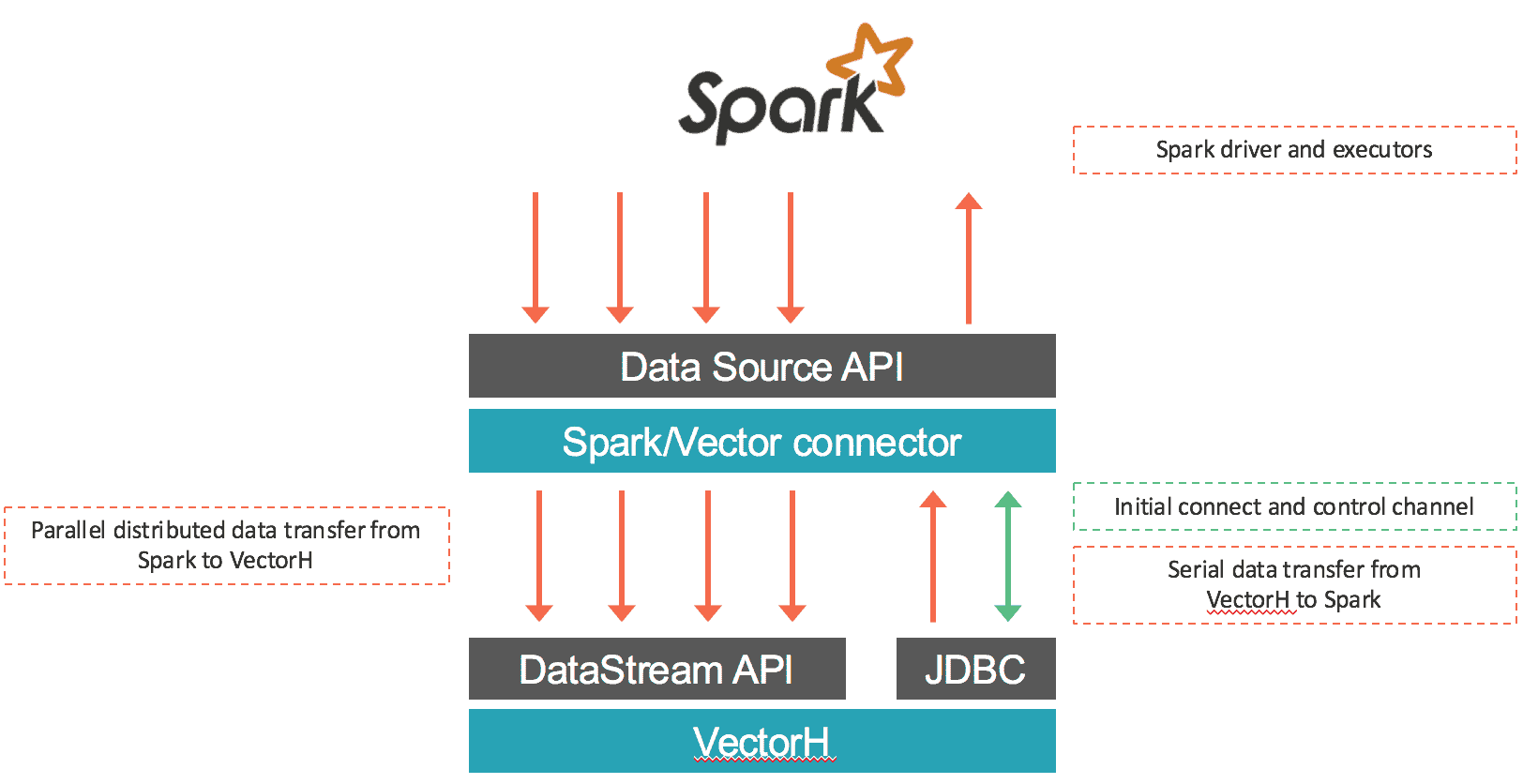
What Else is There?
This latest VectorH release (4.2.3) also includes the following new features:
- YARN support on MapR, in addition to the Cloudera and Hortonworks distributions already certified. With native support in YARN, you can run multiple workloads in the same Hadoop cluster to share the entire pool of resources.
- Per query profile files can be written to a specified directory, including an HDFS directory. This feature provides more flexibility and control to manage and share query profiles across different users.
- New options to display the status of cluster services, including basic node health, Kerberos access if enabled, MPI access, HDFS Safemode, and HDFS fsck.
- A new option to create MinMax indexes on a subset of columns as well as improved memory management of MinMax, resulting in lower CPU and memory overhead.
Learn more at https://www.actian.com/products/ or contact sales@actian.com to speak with a representative.
Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.
Subscribe
Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live
- It’s all up to you – Change your delivery preferences to suit your needs