High-Performance Real-Time Analytics on Hadoop Data
Mary Schulte
December 27, 2017

The Challenge
I have spent many years working with Actian’s customers on database solutions and thought it’d be useful to discuss a recent customer experience at a large media company (I will call it “XYZCo”). This experience is similar to what I continue to see with other customers and the lessons learned apply to both Hadoop and non-Hadoop use cases alike.
In this instance, the Big Data Analytics team at XYZCo came to Actian because they needed high-performance real-time analytics for their Hadoop data, and their current systems were not able to meet business expectations. They were under tremendous pressure to enhance the productivity of their data analysts as analytics on some large data sets would never finish and they needed to reduce data processing overhead and delays to enable real-time data warehouse analytics and reporting.
The Situation
The customer had two very large fact and dimension tables in their database. To answer business questions about customer churn, lifetime value, and market, they needed to join the two together to run queries.
Because legacy databases and Hadoop solutions are so inefficient at joining data (sometimes large joins never finish), XYZCo had adopted a practice of joining the tables together and creating an intermediate pre-joined/materialized table, against which subsequent queries were run. This methodology functioned but it had several problems: the pre-join table, materialization, was HUGE; it was exponentially the size of table1 and table2 (not just copies of table1 plus table2), plus immediately after creation, the materialization was “stale”; it could not be constantly updated from ever-changing table1,table2, but remained with the old values at the time of creation. Furthermore, the query performance against this materialization was not that great and they had some queries that just wouldn’t work at all… the data was just too big.
Furthermore, this customer had large volumes of structured data in a Hadoop data store. They were currently using Hive along with SQL-based analytics tools, including Tableau. The customer was used to pre-joining data across multiple source tables with the “perceived” benefit of simpler/faster querying by other tools and processes downstream. Plus, most of these aggregates/joins were exported to CSV for input into other tools or materialized for “perceived” simpler SQL, because the schema became one flattened source table.
Comparing Solutions
Old-School Materialization Test
XYZCo asked us to also perform the old-school style materialization test using Actian VectorH, Actian’s high-performance columnar SQL database that runs natively in Hadoop, with the idea that this would be a direct comparison to Hive. We did so.
A large part of any materialization is the time incurred doing I/O to write out the large, materialized result set. Although VectorH was much faster than Hive on the join itself, the I/O portion of the entire materialization process dwarfed any join component – fast or slow. Despite being much faster on the join itself, VectorH, in this instance, performed the entire materialization process in about the same timeframe as Hive because so much of the time was writing out the result set, which was the same for both products.
Once built, we ran the queries against the materialization, VectorH was about twice as fast as the other product. Remember for later reading that the materialization is exponential in size to the source tables.
Although impressive, these results pale in comparison to what I will tell you next about the Actian on-demand approach.
Real-Time Analytics With Actian VectorH On-Demand
After performing the above, old-school intermediate materialization test, we wanted to show the customer a better way. We demonstrated that with VectorH, queries against the base data (without intermediate materialization step) with the join done on-demand, was orders of magnitude faster!

Here is the raw data captured on customer Hive and VectorH systems for single run results. Note that the VectorH tests were run on a cluster half the size of the Hive cluster. VectorH exhibits excellent, linear-scalability characteristics so we normalized the results for an equivalent platform.
As mentioned before, a materialization was in the same ball park, VectorH was twice as fast on queries against a materialization. What is more interesting, however, are the cases where Hive was unable to complete any on-demand join scenarios and Actian VectorH showed tremendous speed.

The above benefits are for single runs. What happens in real life situations with hundreds of customer queries and ongoing updating of data?
Below is a table that shows what happens with just 100 and 200 ensuing customer queries, plus one refresh of customer data. Notice that with the speed of VectorH, the old solution, even using pre-materializations is always slower, incurs time for re-materialization, and will just never catch up. The Actian VectorH approach crushes the competitor in performance. This is in addition to the other benefits of the results being on current data rather than stale data, saved disk space, less admin, and so forth.
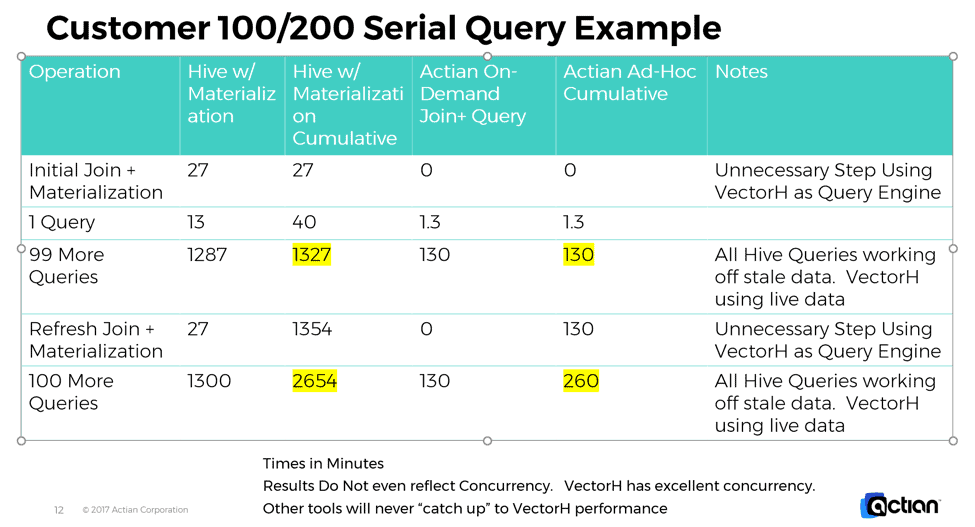
Please also note, that these results don’t even allow for concurrency. VectorH has incredible concurrency. The numbers noted above would be even better for VectorH had we captured such numbers in a concurrent situation.
Conclusion
In the on-demand solution, query results ALWAYS reflected current data and not results from a stale materialization, which allowed for real-time analytics and more accurate results.
Analysts no longer had to wait around for a snapshot to be created and their joins could be done ad-hoc.
Net performance was significantly faster than against a giant pre-aggregation because each query scans only the data it needs rather than every row in a gigantic materialization, resulting in less expensive-I/O and no downtime for rebuilding intermediate materialization.
Views were used to mask join-logic to end users, thereby simplifying queries. Since there is no duplication of data via materialization, storage space is kept to a minimum.
Without a fast JOIN engine like VectorH, this approach is usually impractical for very large data sets.
Next Steps
Want to learn more about Actian VectorH?
You can also download and try Actian Vector yourself. You won’t be disappointed, and if you need help figuring things out, just ask the Community or contact eval@actian.com to request a 30 day evaluation of VectorH with free Enterprise Support.

Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.