What is the Difference Between a Data Analytics Hub and a Lakehouse?





In the opening installment of this blog series — Data Lakes, Data Warehouses and Data Hubs: Do We Need Another Choice? I explore why simply migrating these on-prem data integration, management, and analytics platforms to the Cloud does not fully address modern data analytics needs. In comparing these three platforms, it becomes clear that all of them meet certain critical needs, but none of them meet the needs of business end-users without significant support from IT. In the second blog in this series — What is a Data Analytics Hub? — I introduce the term data analytics hub to describe a platform that takes the optimal operational and analytical elements of data hubs, lakes, and warehouses and combines them with cloud features and functionality to address directly the real-time operational and self-serve needs of business users (rather than exclusively IT users). I also take a moment to examine a fourth related technology, the analytics hub. Given the titular proximity of analytics hub to data analytics hub, it only made sense to clarify that an analytics hub remains as incomplete a solution for modern analytics as does a data lake, hub, and warehouse.
Why? Because, in essence, a data analytics hub, takes the best of all these integration, management, and analytics platforms and combines them in a single platform. A data analytics hub brings together data aggregation, management, and analytics support for any data source with any BI or AI tool, visualization, reporting or other destination. Further, a data analytics hub is built to be accessible to all users on a cross-functional team (even a virtual one). The diagram below shows the relationship between the four predecessors and the data analytics hub (it will look familiar to you if you read installment two of this series).
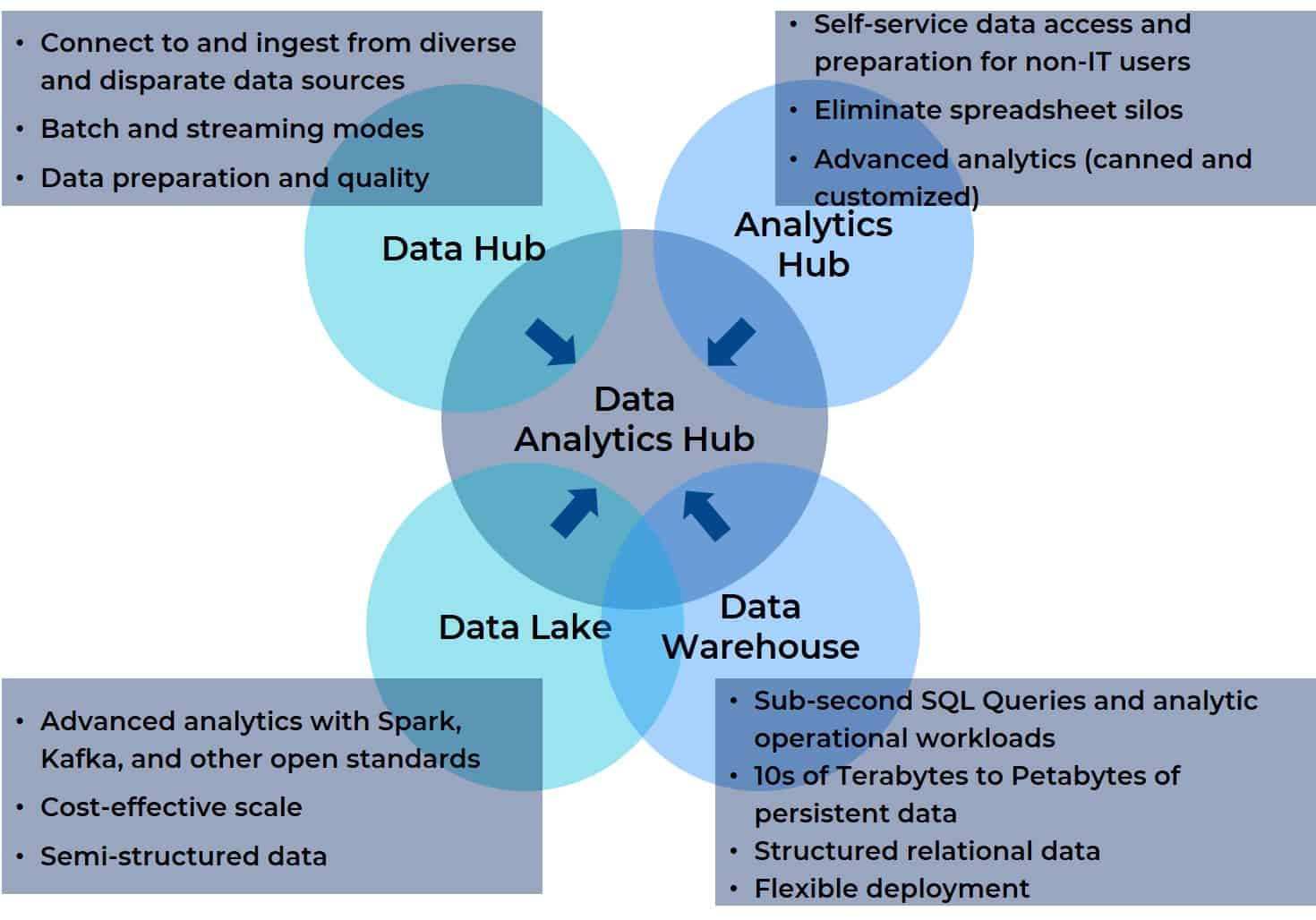
Wait…What About Data Lakehouse?
Last week, I had the privilege of hosting Bill Inmon, considered the father of data warehousing for a webinar on modern data Integration in cloud data warehouses. Needless to say, there were lots of questions for Bill, but there was one that I thought deserved focused discussion here: What is a data lakehouse, and how is it different from a data lake or data warehouse?
Let’s start with the most obvious and a dead giveaway from the name: a data lakehouse is a combination of commodity hardware, open standards, and semi-structured and unstructured data handling capabilities from a data lake and the SQL Analytics, structured schema support, and BI tool integration found in a data warehouse. This is important because the question is less how a data lakehouse differs from a data lake or data warehouse and more how is it more like one or the other. And that distinction is important because where you start in your convergence matters. In simple mathematical terms if A + B = C then B + A = C. But in the real world this isn’t entirely true. The starting point is everything when it comes to the convergence of two platforms or products, as that starting point informs your view of where you’re going, your perception of the trip, and your sense of whether or not you’ve ended up where you expected when you’ve finally arrived at the journey’s end.
Speaking of journeys, let’s take a little trip down memory lane to understand the challenges driving the idea of a data lakehouse.
Historically, data lakes were the realm of data scientists and power users. They supported vast amounts of data — structured and unstructured — for data exploration and complicated data science projects on open standard hardware. But those needs didn’t require access to active data such as that associated with the day-to-day operational business process. They often became science labs and, in some cases, data dumping grounds.
Contrast that with the historical needs of business analysts and other line of business (LOB) power users. They were building and running operational workloads associated with SQL analytics, BI, visualization, and reporting, and they required access to active data. For their needs, IT departments set up enterprise data warehouses, which traditionally leveraged a limited set of ERP application data repositories intimately tied to day-to-day operations. IT needed to intermediate between the data Warehouse and the business analysts and LOB power users, but the data warehouse itself effectively provided a closed-feedback-loop that drove insights for better decision support and business agility.
As digital transformation has progressed, though, needs changed. Applications have become more intelligent and they permeate every aspect of the business. Expectations for data lakes and data warehouses have evolved. The demand for real-time decision support has reduced the data warehouse/ERP repository feedback loop asymptotically, to the point where it approaches real-time. And the original set of ERP repositories are no longer the only repositories of interest to business analysts and LOB power users – web clickstreams, IoT, log files, and other sources are also critical pieces to the puzzle. But these other sources are found in the disparate and diverse datasets swimming in data lakes and spanning multiple applications and departments. Essentially, every aspect of human interaction can be modelled to reveal insights that can greatly improve operational accuracy — so consolidating data from a diverse and disparate data universe and pulling it into a unified view has crystalized as a key requirement. This need is driving convergence in both the data lake and data warehouse spaces and giving rise to this idea of a data lakehouse.
Back to the present: Two of the main proponents for data lakehouses are databricks and Snowflake. The former approaches the task of platform consolidation from the perspective of a data lake vendor and the latter from the perspective of a data warehouse vendor. What their data lakehouse offerings share is this:
- Direct access to source data for BI and analytics tools (from the data warehouse side).
- Support for structured, semi-structured and unstructured data (from the data lake side).
- Schema support with ACID compliance on concurrent reads and writes (from the data warehouse side).
- Open standard tools to support data scientists (from the data lake side).
- Separation of compute and storage (from the data warehouse side).
Key advantages shared include:
- Removing the need for separate repositories for data science and operational BI workloads.
- Reducing IT administration burden.
- Consolidating the silos established by individual BI and AI tools creating their own data repositories.
Emphasis is Everything
Improving the speed and accuracy of analysis on large complex datasets isn’t a task for which the human mind is well suited; we simply can’t comprehend and find subtle patterns in truly large, complex sets of data (or, put another way, sorry, you’re not Neo and you can’t “see” the Matrix in a digital data stream). However, AI is very good at finding patterns in complex multivariate datasets — as long as data scientists can design, train, and tune the algorithms needed to do this (tasks for which their minds are very well suited). Once the algorithms have been tuned and deployed as part of operational workloads, they can support decision-making done by humans (decision support based on situational awareness) or done programmatically (decision support automated and executed by machines as unsupervised machine-to-machine operations). Over time, any or all of these algorithms may need tweaking based on a pattern of outcomes or drift from expected or desired results. Again, not that I feel the need to put in a plug, these are tasks for which the human mind is well suited.
But go back to the drive for convergence and consider where the data lakehouse vendors are starting. What’s the vantage point from their perspective? And how does that color the vendor’s view of what the converged destination looks like? Data lakes have historically been used by data scientists, aided by data engineers and other skilled IT personnel, to collect and analyze the data needed to handle the front end of the AI life cycle, particularly for Machine Learning (ML). Extending that environment means facilitating the deployment of their ML into the operational workloads. From that perspective, success would be a converged platform that shortens the ML lifecycle and makes it more efficient. For business analysts, data engineers, and power users, though, playing with algorithms or creating baseline datasets to train and tune is not part of their day job. For them, additively running ML as part of their operational workloads, inclusive of the additional diverse and disparate datasets, is what matters.
While data scientists and data engineers may not be in IT departments proper, they are not the same as non-IT end-users. Data lakes are generally complex environments to work in, with multiple APIs and significant amounts of coding, which is fine for data scientists and engineers but not fine at all for non-IT roles such as business and operational analysts or their equivalents in various LOB departments. They really need convergence that expands a data warehouse to handle the operationalized ML components in their workloads on a unified platform — without expanding the complexity of the environment or adding in requirements for lots of nights and weekends getting new degrees.
Are We Listening to Everyone We Need To?
I’ve been in product management and product marketing and, at the end of the day, the voice that carries the furthest and loudest is the voice of your customers. They’re the ones who will always best define the incremental features and functionality of your products. For data lake vendors it’s the data scientists, engineers and IT; for data warehouse vendors, it’s IT. Logically, the confines of the problem domain are limited to these groups.
But guess what? This logic misses the most important group out there
That group comprises the business and its representatives, the Business and Operational Analysts and other power users outside of IT and engineering. The data lake and data warehouse vendors — and by extension the data lakehouse vendors — don’t talk to these users because IT is always standing in the middle, always intermediating. These users talk to the vendors of BI and Analytics tools and, to a lesser extent, the vendors offering data hubs and analytics hubs.
The real issue for all these groups involves getting data ingested into the data repository, enriching it, running baseline in-platform analysis and leveraging existing tools for further BI analysis, AI, visualization and reporting without leaving the environment. The issue is more acute for the business side as they need self-service tools they currently don’t have outside of the BI and Analytics tools (which often silo data within the tool/project instead of facilitating the construction of a unified view that can be seen by all parties).
Everyone agrees there needs to be a unified view of data that all parties can access, but the agreement will not satisfy all parties equally. A data lakehouse based on a data lake is a great way to improve the ML lifecycle and bring data scientists closer to the rest of the cross functional team. However, that could be accomplished simply by moving the HDFS infrastructure to the cloud and using S3, ADLS, or Google Cloud Store plus a modern cloud data warehouse. Such a solution would satisfy the vast majority of use cases operationalizing ML components to workloads. What’s really missing from both the data lake- and data warehouse-originated lakehouses is the functionality of the data hub and analytics Hub, which is built into the data analytics hub.
Conclusion: A Lakehouse Offers Only a Subset of the Functionality Found in a Data Analytics Hub
The diagram with which we started illustrates how a data analytics hub consolidates the essential elements of a data lake, data warehouse, analytics hub, and data hub. It also illustrates the shortsightedness of the data lakehouse approach. It’s not enough to merge only two of the four components users need for modern analytics, particularly when the development of this chimera is based on feedback from a subset of the cross functional roles that use the platform.
In the next blog we’ll take a deeper look at the use cases driven by this broader group of users, and it will become clear why and how a data analytics hub will better meet the needs of all parties, regardless of whether they are focused on ML-based optimizations or day-to-day operational workloads.



Stay connected
Data insights delivered to you.
(i.e. sales@..., support@...)