Using a Healthcare Data Analytics Hub for Value-Based Care
Actian Corporation
November 10, 2021

Last August I wrote a blog about the data at the Beating Heart of Healthcare and introduced the concept of the healthcare data analytics hub. Frequent readers will remember that a healthcare data analytics hub provides a unified, cloud-based platform that supports access, enrichment, analysis, visualization, and reporting services to both automate and act on healthcare delivery, operations, and administration activities. What distinguishes a healthcare data analytics hub from its forerunners—data warehouses, data lakes, and data hubs—is that it provides the tools to transform data from disparate sources many of which are external to the organization with sources internal to the organization that is often siloed by department (e.g., systems from Allscripts, Epic, and many others) into insights intended for a range of functional roles residing outside the IT department within the organization as well as external to the organization. The figure below provides a conceptual illustration of the healthcare data analytics hub.
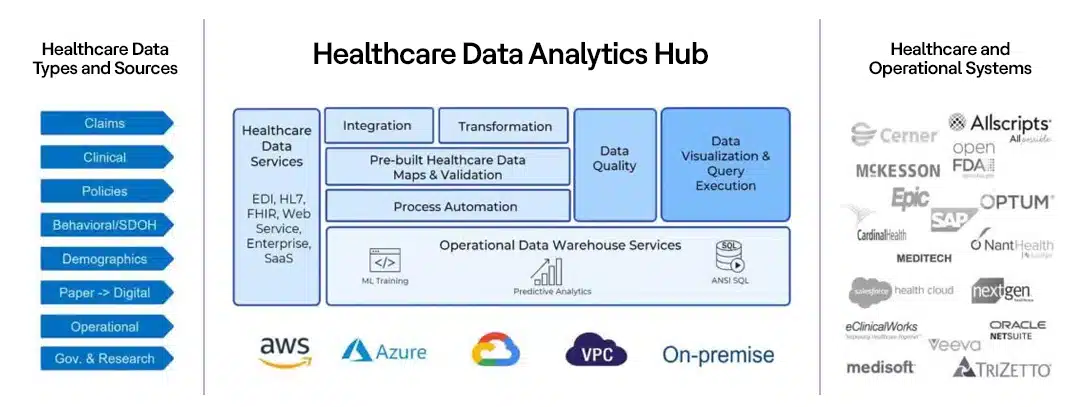
Why does healthcare really need this? Because the move from a fee-for-service to value-based care model requires insights that are much harder to gain without the efficiencies you can only identify by bringing together diverse and disparate clinical, financial, and operational data from across the organization as well as outside it. And without those insights, the improvement in outcomes and the operational efficiencies that value-based care promises to deliver will themselves be harder and more costly to achieve. This is only possible with a healthcare data analytics hub.
The Healthcare Data, Knowledge, and Insights Gap
Today, healthcare professionals think and work differently than they did 20 years ago. Gone are the days when care delivery professionals, healthcare provider administrators, insurance underwriters, claims managers, claims adjusters, and others dealt exclusively with a mountain of paper forms and reports. The required level of digital literacy has dramatically changed. Look at the average job requirements posted for, say, a provider network manager. Often you will find that they must be fluent in SQL and able to manipulate, analyze, and visualize data in business intelligence (BI) tools such as Looker and Tableau. It’s not that they’ve all abandoned their Excel spreadsheets; it’s simply that the demands of the job have grown more expansive. Elsewhere in the organization, clinicians and business analysts may be using JavaScript for modeling; actuarial scientists may be using Python and Plotly. But here’s the thing: They know how to perform sophisticated analytics, but rarely do they know how to access or enrich the disparate datasets upon which they want to run their analytics. They have many of the skills necessary to add real value, but their ability to add value depends upon their ability to access digital data.
And that’s the rub, gaining access to the data. In many organizations, authorization alone is a huge barrier to data access, and given that different data sets are owned by different data stewards and often housed in different departmental silos, there’s no way to gain universal access to—or even a comprehensive view of—all the data that exists within the organization. Further, the myriad of proprietary systems and their different access standards and methodologies require skills that often only IT Integration specialists or data engineers possess. These IT specialists tend to be oversubscribed, and the demands placed on them mean that often they are thrashing. Between the difficulties in accessing data and the difficulties accessing the IT resources who could help, organizations often find themselves with stale or incomplete datasets from which users at every level can only gain insights that are also stale and incomplete.
Closing the Gap
So how can data engineers working in tandem with a healthcare data analytics hub better support their business partners? Here are seven key ways that a healthcare organization can foster more effective engagement:
- Enable Service-Oriented Connectivity. In many organizations, legacy applications and data repositories are often connected on a point-to-point basis, an approach that hamstrings connectivity and drives inefficient use of the data engineers. Data engineers should instead make each application and data repository available as a reusable service that other applications and repositories can access through a published interface.
- Catalog All Services. Make it easier for users to know what services are available, where to go, and how to connect to services by publishing a directory with guidelines on how to use each service.
- Build and Manage Data Models. Many of the data repositories will have fixed and known schemas, and some of the more modern apps will have web services APIs and JSON data payloads with descriptions of the data—but what is really needed is an understanding of what the data models look like, taking into account all the data across this catalog of services. This activity will need to be a joint venture between the data engineer and their business and operations analysts, app developers, IT integration specialists, and data scientists.
- Establish Data Steward Communities. Given the myriad of data access and ownership issues—ranging from longstanding “this is my sandbox” attitudes held by different stakeholders about different applications and data, inconsistent internal rules about data sharing, legitimate HIPAA constraints, and more—it is incumbent upon a data engineer to develop communities of data stewards who can meet to discuss and decide upon questions relating to data ownership, the parameters for access, and how, when, and under what conditions part or all of that data can be accessed. These communities must be mapped against a catalog of services to ensure that the services can access the data required. Generally, starting with a “Do No Harm” attitude—as in “Do not perturb existing data repositories”—will facilitate access and reduce the chances of data misuse.
- Empower Superusers With Self-Service. First, what’s a superuser? A superuser is an umbrella term I’m using to denote all the business analysts, clinicians, and others that would be eager and able to ingest, enrich, and analyze complex datasets if you just give them the tools to do it (and have taken care of the first four points above). Again, these users tend to be technical and capable of using sophisticated data integration and management tools, as long as they involve little or—better yet—no coding.
- Support Exploration. Once a data model has been developed, the services have been cataloged, and data stewards have allowed data to be copied or virtualized into a separate aggregation point, the data engineer should use cloud services to ensure that superusers have inexpensive, easily set up and torn down sandboxes in which to bring together the data, cleanse it, and engage with it.
- Operationalize Data Pipelines and Analytics Assets. Fruitful explorations by superusers will need to be captured and documented for future reuse. The documentation should indicate how data was ingested, what modeling was used, and which integration services were leveraged, as this information creates an integration flow that can be automated as a data pipeline. The data processed—whether it be ad hoc queries or something that creates refreshed dashboards—should be orchestrated and its output cataloged as a set of analytics assets. Automation and repeatability ensures reuse and the highest ROI.
Setting the Stage for Insights to Help Shift from Fee-for-Service to Value-Based Care
A healthcare data analytics hub provides a centralized and standardized platform to help the data engineer achieve tasks one through four and provides direct support for tasks five through seven. The data models, catalog, and data steward communities (tasks two through four) should be developed independently of a healthcare data analytics hub, but the healthcare data analytics hub self-service functions for superusers (task five) need to enable ingestion and data preparation—quickly and easily—from any service in the catalog (using the rules defined by the data steward community). The data model (from task three) should be used to guide pipeline development and automation (tasks six and seven).
As these tasks are completed, the healthcare data analytics hub becomes a platform that increases the operational efficiency of data analytics superusers throughout the operational ecosystem, which in turn drives the following benefits for the organization:
- It removes the continuous wait for data engineering when it comes to mundane tasks and eliminates many of the manual report production-tasks associated with stove-piped healthcare platforms, legacy enterprise data warehouses, and data marts.
- It simplifies and accelerates ongoing dashboard and reporting projects, particularly where there are requests for minor changes and additions to reports (such as adding a new visualization of the same data or adding an additional dataset).
- It enables users to explore new datasets or use a different visualization tool than they normally use because they are working on a new project or with a new group that uses different datasets and tools.
- It empowers superusers to improve the quality of their data without perturbing source systems or relying on the data engineer to cleanse the data. Numerous studies and surveys have shown that data preparation and discovery consume more of these superusers’ time and energy than any other activity.
- It facilitates cross-functional teamwork by providing a neutral common ground that all team members can use as a sandbox with a unified data set. At the same time, the flexibility of the healthcare data analytics hub ensures that all users can use BI and analytics tools that they are accustomed to using.
These are straightforward benefits yet they represent only a fraction of the benefits that a healthcare data analytics hub brings to the table. The overarching point is that a healthcare data analytics hub enables a data engineer to support far more requests—across multiple projects—with better quality at a far lower cost. The cost reduction benefits themselves derive from two aspects of the healthcare data analytics hub: The hub isn’t a capital expense that an organization needs to depreciate over time: Access to the hub can be purchased on a per-project basis. Moreover, the duration of a project can be as long or short as it needs to be. You never pay for more than you need. The clinicians and analysts using the hub quickly realize the productivity improvements and cost savings and incrementally use it more for additional projects, leading to rapid adoption.
At the heart of all challenges in moving from fee-for-service to value-based models, there is a need to take a data-driven approach to better understanding how financial, operational, and clinical performance interrelate, how underlying assets, human and machine, can be brought to bear on outcomes, and on what those patient and program outcomes really are. The insights necessary to drive change can only be found when the organization’s data engineers and superusers can look in and across the various systems that are cataloged, modeled, and made available for analysis through the healthcare data analytics hub.
Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.
