Database History in the Making: Ingres Meets X100
Emma McGrattan
December 19, 2017

Doug Inkster is an Actian Fellow with a long history in the database market, starting with IDMS in the 1970s and moving to Ingres in the 1990s. We asked him to reminisce about the most exciting times in his long career. Here are some of his thoughts:
In my 40+ years of working with and developing database management software, one of the best days was meeting Peter Boncz and Marcin Żukowski for the first time. I was in Redwood City leading query optimizer training for the performance engineering team at Ingres Corp. (now Actian), and Peter and Marcin were in the Bay Area to give a lecture at Stanford University.
Dan Koren, director of performance engineering, invited them to discuss the MonetDB/X100 technology, which was the subject of Marcin’s Ph.D. research under Peter’s guidance. Dan was a great fan of the MonetDB research done largely by Peter at CWI (the Dutch government-funded centre for research in mathematics and computer science) in Amsterdam and X100 was a follow-on from MonetDB.
The day started with just the four of us in a conference room at Ingres headquarters and Marcin kicked it off with a quick overview of their Stanford presentation. Peter & Marcin experimented by comparing a variety of row store DBMS’s running the first query from the TPC H benchmark to a hand-written C program equivalent to the same query. The hand-written program was far faster than the fastest DBMS and led to the X100 research project (thus named because of their “modest” goal of beating current database performance by a factor of 100).
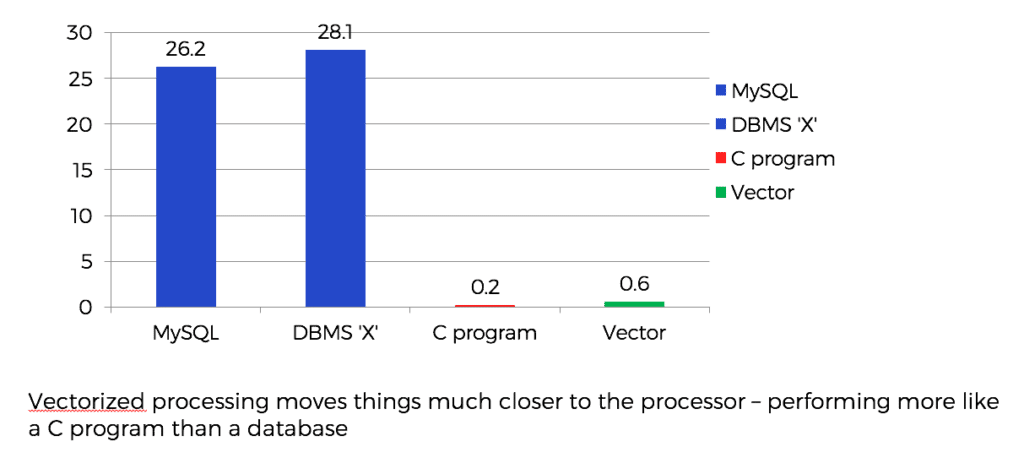
Their research quickly concluded that the complexity of row stores was not limited solely to their representation on disk. The processing of row store data once in memory of a database server is still highly complex. The complexity of the code defies cache attempts to take advantage of locality and in-order instruction execution. In fact, some column stores suffer the same processing problems by converting the column store format to rows once the data is in server memory. Addressing the columns in question, then performing the operations cell by cell consumes many machine cycles.
They had already addressed some of the problem issues with MonetDB, but it still was bound by issues of query complexity and scalability. X100 introduced the idea of processing “vectors” of column data at a single time and streaming them from operator to operator. Rather than computing expressions on the column of one row at a time, or comparing column values from single rows at a time, the X100 execution engine processes operators on vectors of column values with a single invocation of expression handling routines. The routines take the vectors as parameters and consist of simple loops to process all the values in the supplied vectors. This type of code compiles very well in modern computer architectures, taking advantage of the pipelining of loops, benefitting from locality of reference and, in some cases, introducing SIMD instructions (single instruction, multiple data) which can operate on all values of the input vector at the same time.
The result was the concurrent reduction of the instructions per tuple and cycles per instruction, leading to a massive improvement in performance. I had remembered the old scientific computers of the 1970s (CDC, Cray, etc.), which also had the ability to execute certain instructions on vectors of data simultaneously. Back in the day however, those techniques were reserved for highly specialized scientific processing – weather forecasting and so forth. Even the modern re-introduction of such hardware features was more directed towards multi-media applications and computer games. The fact that Peter and Marcin had leveraged them to solve ancient database processing problems was brilliant!
Of course, there was more to their research than just that. A major component of X100 was the idea of using the memory hierarchy – disk to main memory to cache – as effectively as possible. Data is compressed (lightly) on disk and only decompressed when the vectors of values are set to be processed. Sizes of vectors are optimized to balance the I/O throughput with the cache capacity. But for me, the excitement (and amusement at the same time) was in seeing hardware designed for streaming movies and playing Minecraft could be used so effectively in such a fundamental business application as database management.
The subsequent uptake of the X100 technology by Ingres led quickly to record breaking (smashing was more like it) TPC H performance and some of the most enjoyable years of my professional career.
Note: Ingres is still a popular row-oriented RDBMS supporting mission critical applications, while X100 delivers industry-leading query performance in both the Actian Vector analytic database and the Actian X hybrid database, a combination of Ingres and X100 technologies capable of handling both row-based and column-based tables.

Subscribe to the Actian Blog
Subscribe to Actian’s blog to get data insights delivered right to you.
- Stay in the know – Get the latest in data analytics pushed directly to your inbox.
- Never miss a post – You’ll receive automatic email updates to let you know when new posts are live.
- It’s all up to you – Change your delivery preferences to suit your needs.